

核心观点
作为数据中心互联的核心组件,交换芯片用于处理数据交换和报文转发,占交换机成本比例达30%以上。我们看好26年起交换芯片在AI驱动下开启二次成长:1)万卡级以上集群需要更加稳定可靠的网络系统,推动数据中心Scale out交换机向更高容量、速率发展,Scale out交换芯片有望量价齐升;2)超节点架构或为国产算力追赶海外算力的破局之道,超节点放大集群内Scale up作用,交换芯片配比通常高于Scale out,未来或催生大量交换芯片需求。我们测算28年国产交换芯片市场空间有望达到242亿元,26-28年CAGR为96%,建议关注海外龙头及国内自研技术领先的芯片商。
空间:28年国产Scale out/up交换芯片市场预计达113/129亿元
我们看好交换芯片市场进入新一轮增长空间:一方面,随着AI集群规模向万卡及以上扩张,为维持服务器之间东西向流量的传输,Scale out交换机及其芯片用量随计算节点的增加而加速放量;另一方面,超节点架构强化了单节点的计算能力,机柜内部GPU数量大幅增加,且GPU之间的互联带宽更高、延迟更低,使得Scale up相比于Scale out有更多的交换芯片需求。从空间来看,我们预计:1)2028年国产Scale out交换芯片市场空间有望达到113亿元,26-28E CAGR为60%;2)2028年国产Scale up交换芯片市场规模有望达到129亿元,26E-28E CAGR为212%。
格局:中国芯与海外尚存代际差距,目前国内市场由海外巨头把持
从产品来看,目前博通、英伟达和思科均已发布102.4T、量产51.2T容量的交换芯片,而国内盛科等厂商最高量产水平为25.6T,差距尚存。从格局来看,交换芯片市场高度集中,国内份额此前由海外巨头把持:1)全球来看,据QYResearch数据, 2024年博通、Marvell、思科市占率合计达到77.14%;2)国内来看,据灼识咨询,除自用交换芯片厂商(华为、思科)外,2020年中国商用交换芯片市场上,博通、Marvell和瑞昱合计市占率为97.8%,国产厂商盛科通信市占率1.6%。
与市场不同的观点
市场或担忧海外龙头长期主导国内市场,导致国产交换芯片厂商市场份额拓展受限,但我们认为:1)技术差距客观存在,但国产厂商正加速技术追赶,目前中兴、盛科等公司高端产品已落地应用并实现较好性能;2)供应链安全角度看,未来芯片国产化要求或继续提升,大型CSP及运营商亦有望自发进行国产化适配前置化;3)超节点趋势或重塑格局,其一在于超节点开辟Scale up这一新兴赛道,国产厂商与海外龙头处在同一起跑线,其二在于目前协议标准尚未统一,国内有望跑出如UALink、ALS等开放标准,而这一过程离不开GPU及交换芯片的深度适配,国产厂商或更具配合意愿。
投资逻辑
我们看好:1)北美云厂商及国内互联网厂商对未来的资本支出延续乐观,数据中心建设或将增加对交换机等网络设备的需求;2)超节点方案有望在追赶海外算力的背景下规模放量,其中Scale up是核心增量环节,交换芯片用量有望大幅提升。我们梳理全球交换芯片产业链,具体请见研报原文。
风险提示:1)云厂商资本支出不及预期;2)超节点方案落地进程不及预期;3)本研报中涉及到未上市公司或未覆盖个股内容,均系对其客观公开信息的整理,并不代表本研究团队对该公司、该股票的推荐或覆盖。
正文
报告核心观点
核心推荐逻辑
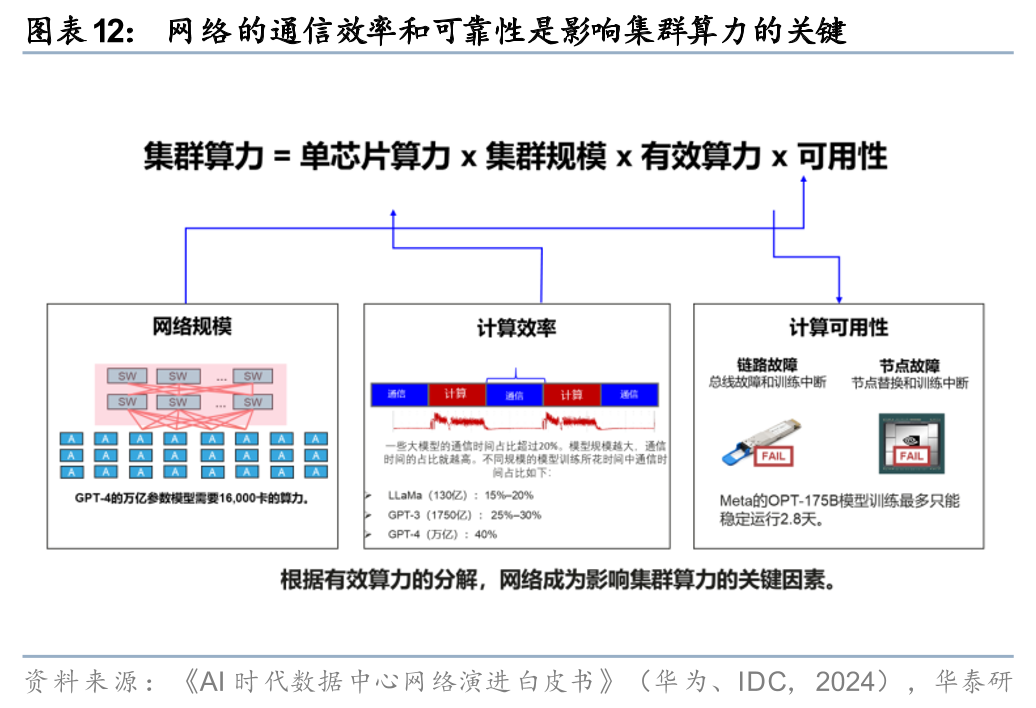
交换芯片是数据中心互联的核心组件,AI训推共振背景下交换芯片有望迎来量价齐升。交换芯片用于交换处理大量数据及报文转发,是决定交换机带宽、端口速率和时延的核心器件,占交换机成本的比例超过30%。我们认为,AI算力训推共振或将推动算力集群规模扩张:1)训练侧,遵循Scaling Laws,随着AI大模型参数规模突破十万亿级,训练Token规模或迈入数十万亿,迫使集群规模向万卡甚至十万卡级跨越;2)推理侧,随着多模态应用的普及,推理端对于Token的消耗量亦将呈指数级增长。AI训推共振使得算力集群的互联复杂度大幅提升,届时网络的稳定性、传输效率将成为决定算力利用率的关键。我们看好算力节点的增长带动交换芯片的刚性需求放量,且为适配高带宽、低延迟的智算需求,交换芯片向更高端化演进,单芯片价值量亦将有所提升。具体而言:
Scale out:集群规模扩张 容量/带宽升级,构成Scale out交换芯片增长动能。随着算力集群向万卡、十万卡级别延伸,传统的数据中心网络架构正加速向扁平化的Leaf-Spine架构演进,由于叶脊交换机与算力节点数量存在比例关系,算力节点增加将带动数据中心交换机及其交换芯片出货量放量。同时,AI 分布式训练产生的海量“东西向流量”对吞吐能力及无损传输提出了更高要求,倒逼交换芯片规格快速迭代。目前博通、英伟达和思科最新一代芯片交换容量已达到102.4Tbps,博通和思科产品率先支持1.6T端口速率,未来或将继续提升。综上,物理规模扩张带来的“量增”与性能升级驱动的“价升”深度共振,构成了 Scale-out 交换芯片需求增长的核心动能。
Scale up:超节点架构渗透以运力补算力,Scale up交换芯片需求有望快速增加。超节点架构通过多卡协同以及我国领先的通信技术及工程实现能力,有望在集群层面实现持平甚至赶超海外超节点的性能,亦能通过系统级架构提高每单位算力的资本效率。根据冯诺依曼计算机体系架构,计算、存储、网络三者需保持系统级平衡,我们认为,Scale up是超节点的核心增量,而基于国产卡与海外卡的算力差距,若需在网络上进行补齐,则国产超节点中Scale Up交换芯片与GPU 的比例或高于海外。
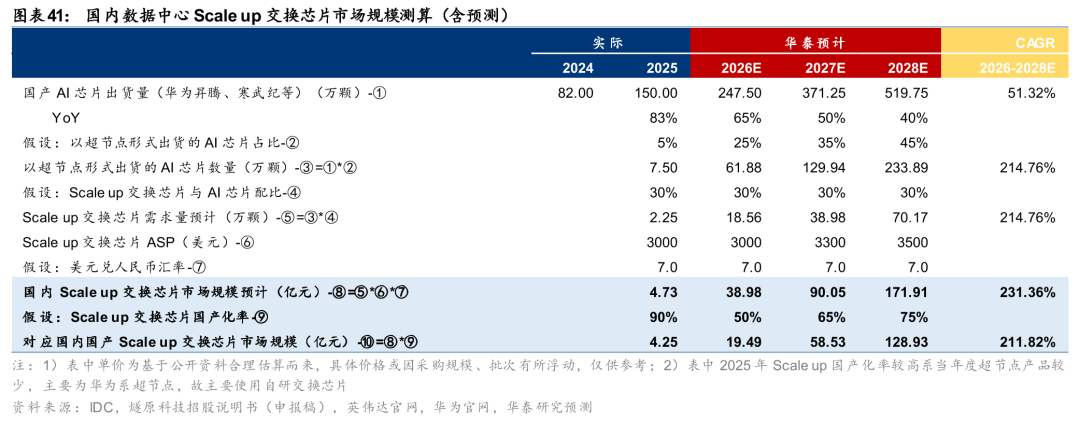
我们预计,2028年国产Scale out/up交换芯片市场规模有望分别达到113/129亿元。数据中心交换芯片应用场景主要为Scale out和Scale up,我们测算:1)Scale out:到2028年国内数据中心Scale out交换芯片市场有望达174亿元,26-28E CAGR为34%;届时预计国产化率达到65%,对应国产Scale out交换芯片市场达113亿元,26-28E CAGR为60%;2)Scale up:预计超节点带动Scale up交换芯片规模增长,到28年我国数据中心Scale up交换芯片市场有望达172亿元,26-28E CAGR为231%;届时预计国产化率达到75%,对应国产Scale up交换芯片市场达129亿元,26-28E CAGR为212%
投资维度,我们建议持续跟踪海外龙头厂商前沿进展:
1)交换芯片集成度、复杂度日益提升,需要长期的技术积累和研发投入,且芯片进入供应链后生命周期长达8-10年,具备较高的客户粘性,故行业进入壁垒高。海外龙头目前占据全球大部分份额,2024年博通、Marvell、思科的市占率合计达到77%,我们认为应继续跟踪海外巨头的技术迭代及新品进展;
2)国内市场上,尽管海外厂商市场份额高,但我们认为长期来看海外供应仍存在不确定性,而政策鼓励、技术发展下国产化率有望提高,且超节点架构引入Scale up新赛道,国内交换芯片厂商或更具与CSP厂商底层适配、共建生态的意愿,有望借此提高市场份额。
与市场不同的观点
市场或担心博通、Marvell等为首的海外巨头将长期主导国内交换芯片市场,而国产厂商份额拓展受限,但我们认为未来AI超节点驱动下国内交换芯片格局有望得到重塑:
1)技术差距虽客观存在,但国产厂商正在加速追赶:从实际应用效果来看,截至2025年,中兴凌云、盛科Arctic系列在吞吐量、时延及无损网络适配性方面均已达到海外同档次芯片水平,且均取得不错的试验成果:1)中兴通讯以自研 AI 大容量交换芯片“凌云”为基石,构建 Nebula 星云智算超节点,打造万卡、十万卡超大规模智算集群;2)盛科通信25.6Tbps(Arctic系列)高端旗舰芯片在客户处进入市场推广和逐步应用阶段(截至2025年中报),同时公司参与中国移动OISA 2.0协议,该协议显著降低通信时延至数纳秒,提升GPU片间互联带宽(突破TB级),进一步将超节点互联高带宽域扩展至1024卡。
2)在全球供应链存在不确定性的背景下,交换芯片国产化要求有望提升:类比目前海外GPU进口受限,交换芯片作为支撑大规模算力集群“运力”的核心元件,其供应链稳定性直接关系到算力底座的安全,在这一背景下,国家有望继续增强对关键芯片国产化的要求,同时大型CSP厂商及运营商亦有望自发提早进行国产化适配以规避可能的供应链风险;
3)随着国产超节点起量,国产交换芯片厂商或凭借本土化优势脱颖而出:
a.超节点架构相对传统节点,其Scale up网络的作用被放大,而由于Scale up赛道目前全球尚未形成稳定的格局,协议标准也并未统一,国产厂商实际上与博通等海外巨头处于同一起跑线;
b.区别于英伟达的封闭协议(NVLink),国内有望跑出如UALink、ETH、ALS等开放互联标准,而这一过程离不开CSP、GPU厂商、交换芯片厂商的深度协同;
c.超节点的复杂性要求交换芯片与GPU进行深度的底层适配,本土厂商在底层架构开放及现场调试响应上更具优势,也更具配合意愿。
交换芯片:AI算力网络的“掌上明珠”
解构:交换机的核心元件,AI时代将集成更多功能
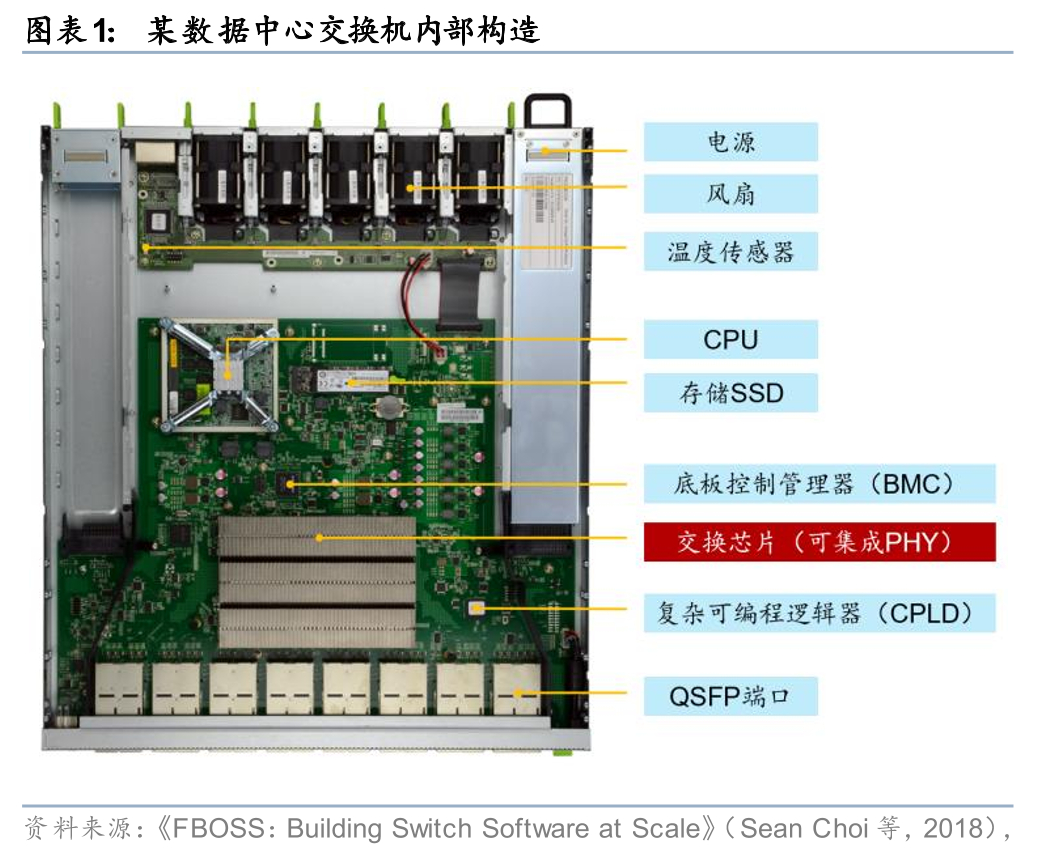
交换芯片用于数据交换及报文转发,是交换机的核心组件。以太网交换机为用于网络信息交换的网络设备,是实现各种类型网络终端互联互通的关键设备。以太网交换机由以太网交换芯片、CPU、PHY、PCB、接口/端口子系统等组成,其中以太网交换芯片和CPU为最核心部件。以太网交换芯片为用于交换处理大量数据及报文转发的专用芯片,是针对网络应用优化的专用集成电路(ASIC)。以太网交换芯片内部的逻辑通路由数百个特性集合组成,在协同工作的同时保持极高的数据处理能力,因此其架构实现具有复杂性。其余组件方面,CPU是用来管理登录、协议交互的控制的通用芯片;PHY用于处理电接口的物理层数据。部分高端以太网交换芯片也将CPU、PHY集成在以太网交换芯片内部。
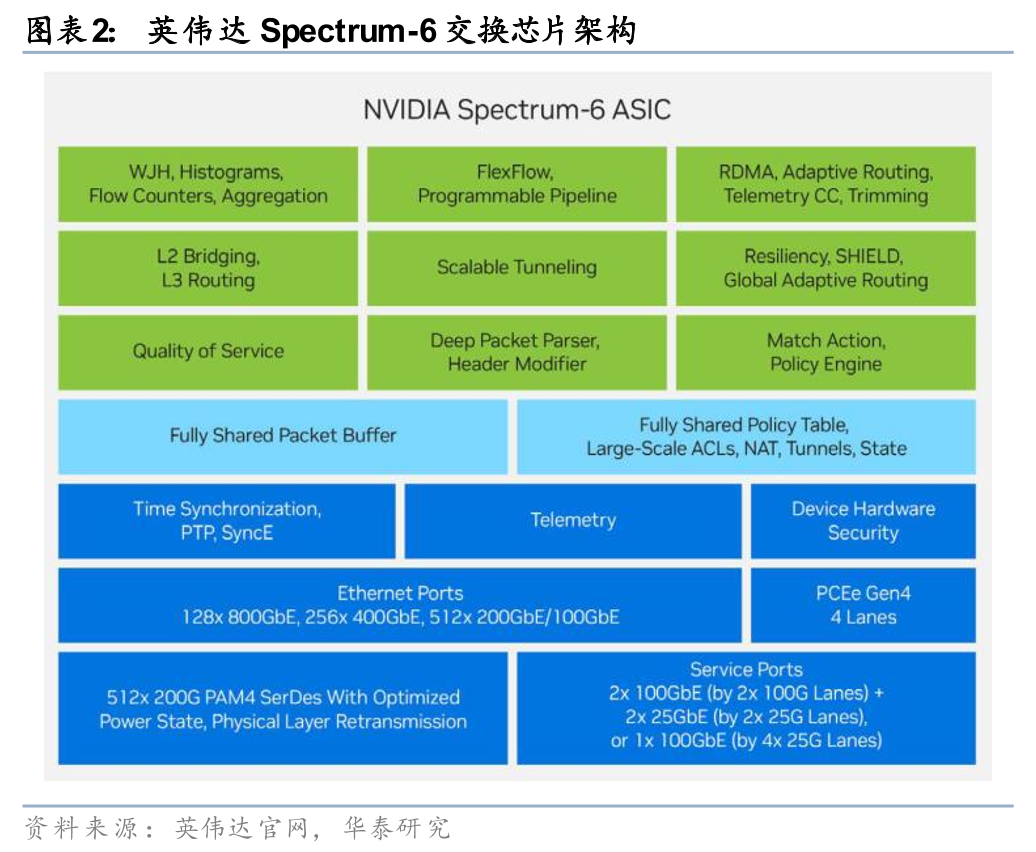
从内部构造看,高性能交换芯片内部核心主要由三大功能区构成:物理与高速接口层、共享缓存区以及数据处理与转发引擎区。以英伟达Spectrum-6交换芯片为例,依次来看:
1)最底层为物理与高速接口层(右下图深蓝色区域),该层的基石是密集排布的高速 SerDes 阵列(如 512通道的200G PAM4),SerDes是决定芯片物理总带宽的基础,负责海量数据的信号转换。紧贴其上的是以太网端口逻辑层(MAC/PCS),它负责将SerDes传来的物理比特流纠错并打包成标准的以太网数据帧,同时具备强大的通道聚合功能,比如该层可将4条200G的SerDes物理通道从逻辑上进行绑定,从而组合成一个800G的高速端口,依托全片512条通道,则可灵活组合成128个800G或者256个400G端口;
2)中层为共享缓存区(Shared Packet Buffer)(右下图淡蓝色区域),作用是依靠大容量片上存储池来应对 AI 分布式训练中极易产生的瞬时突发流量,是实现网络无损传输、防止拥塞丢包的物质基础;
3)顶层为数据处理与转发引擎区(右下图绿色区域),此处除了具备基础的 L2/L3 路由与可编程报文解析流水线,也内嵌了专为 AI 算力集群优化的端到端 RDMA、自适应路由(Adaptive Routing)以及高精度带内遥测(Telemetry)模块。
原理:精准 迅速转发报文,容量/速率/时延为关键指标
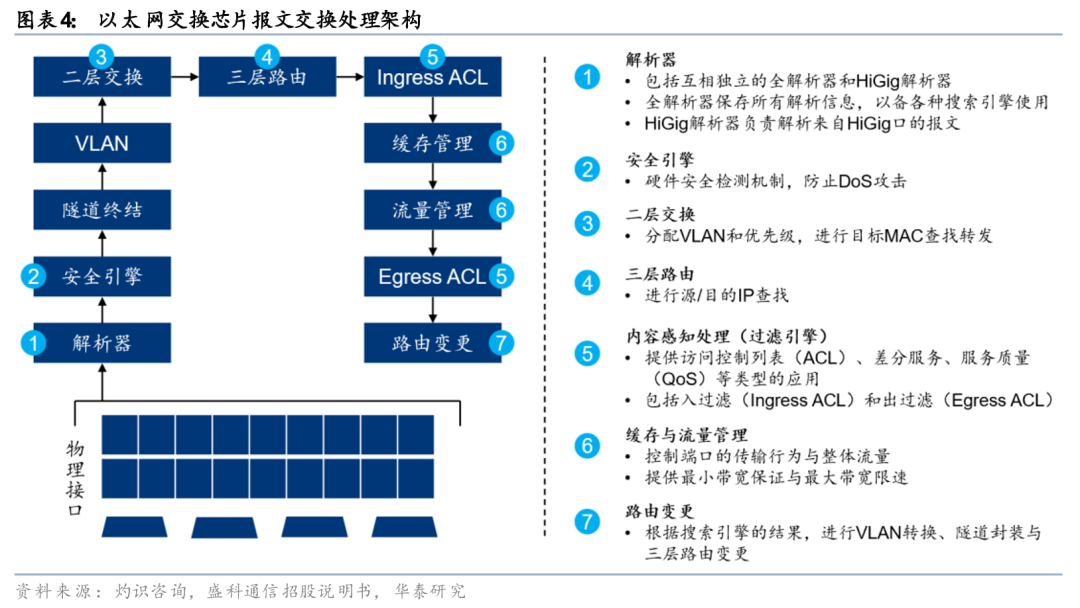
交换芯片主要工作于OSI模型的物理层、数据链路层、网络层和传输层。以太网交换芯片在逻辑层次上遵从OSI模型(开放式通信系统互联参考模型),OSI模型将网络通信功能分为七层,包括物理层、数据链路层、网络层、传输层、会话层、表示层和应用层。以太网交换芯片主要工作在L1至L4层级,即物理层、数据链路层、网络层和传输层:1)物理层(L1):此前讲到,目前高性能交换芯片已集成PHY芯片,交换芯片通过内部集成的高速SerDes阵列,完成海量底层比特流的收发与数字信号转换;2)数据链路层(L2):交换芯片的核心工作层级,提供面向MAC地址的高性能桥接技术(二层转发),负责以太网帧的封装、解封装以及VLAN的隔离与转发;3)网络层(L3):提供面向IP 地址的高性能路由技术(三层路由),通过硬件级路由表项查找,实现跨网段数据包的极速寻址与转发;4)传输层(L4):提供基于 TCP/UDP 端口号的安全策略与精细化管控,包括执行 ACL(访问控制列表)策略,以及针对不同业务优先级的 QoS(服务质量)流量调度与拥塞管理。作为以太网交换机的核心元器件,以太网交换芯片在很大程度上决定了以太网交换机的功能、性能和综合应用处理能力。

交换芯片的工作原理:需要传输的报文/数据包由端口进入以太网交换芯片之后,首先进行数据包头字段匹配,为流分类做准备;而后经过安全引擎进行硬件安全检测;符合安全的数据包进行二层交换或者三层路由,经过流分类处理器对匹配的数据包做相关动作(比如丢弃、限速、修改VLAN等);对于可以转发的数据包根据802.1P或DSCP放到不同队列的buffer中,调度器根据优先级或者WRR等算法进行队列调度,在端口发出该数据包之前执行流分类修改动作,最终从相应端口发出。
交换芯片的主要性能指标包括交换容量、端口速率、特性、表项、缓存、时延等。交换容量取决于芯片的计算能力,也直接决定了设备吞吐量的交换性能,在给定单端口速率的前提下,交换容量直接决定了设备所能提供的端口密度。例如,一颗 51.2Tbps 的交换芯片,可满载支撑64个800G端口或128个400G端口的转发。端口速率的多样化和最高速率决定设备的应用场景和网络位置。特性包括转发特性和安全特性等,决定设备应用的复杂度。表项代表芯片能够容纳的业务规模。缓存代表拥塞场景下报文可在本地缓存的深度。时延代表数据包在芯片停留的时间,决定了网络的效率,需要注意的是,Scale up交换芯片比Scale out交换芯片更看重时延这一指标。

成本:交换芯片占交换机成本的比例在30%以上
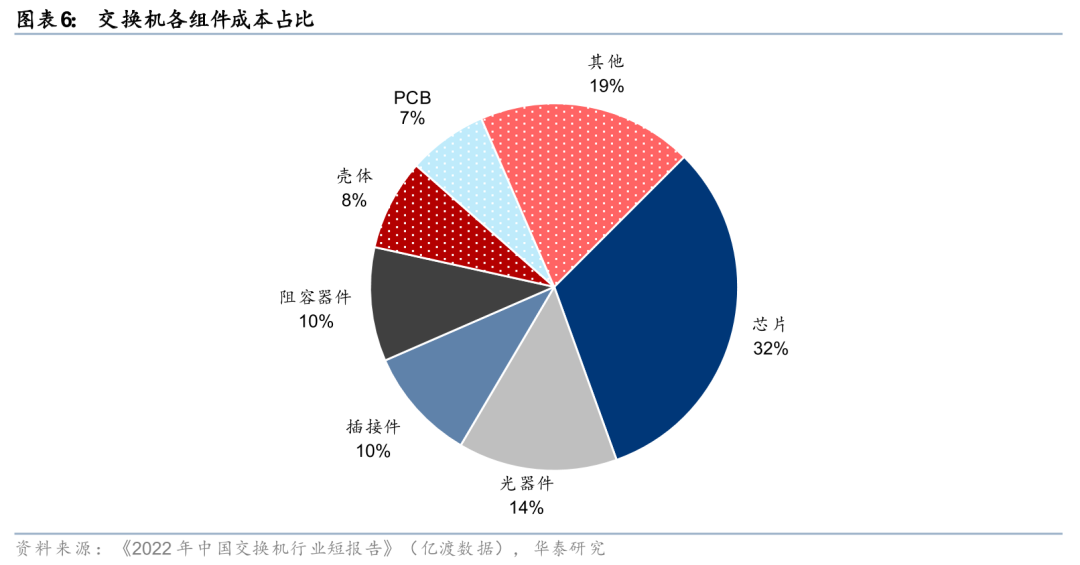
根据亿渡数据《2022年中国交换机行业短报告》数据,从某白盒交换机各组件成本构成来看,芯片类组件所占成本比例最大,达到32%。光器件、插接件、阻容器件、壳体、PCB等重要元器件分别占14%、10%、10%、8%、7%。此外,在大容量、高速率交换机中,交换芯片的成本占比更高。
分类:数据中心场景下对交换芯片的要求更高
根据应用场景的不同,交换机可分为园区交换机和数据中心交换机,二者对交换芯片的需求各有侧重。数据中心交换机专为大型数据中心环境设计,核心目标是支撑海量数据处理、高性能计算和云服务等关键业务。它需要应对高密度服务器集群的互联需求,保障数据在大规模节点间的高速流转,同时满足业务连续性的严苛要求。园区交换机主要面向办公楼宇、企业园区等小型网络环境,其设计定位是为办公设备提供稳定可靠的基础连接。其聚焦于满足电脑、电话、打印机、无线AP等终端设备的日常网络通信需求,在性能与成本间寻求平衡。由于定位不同,两类场景下交换芯片的技术特性存在一定区别:1)交换容量,数据中心场景下需要交换芯片具备更高的交换容量以支持交换机连接大量服务器,目前最高可达102.4Tbps,而园区场景下对交换容量的需求较低;2)性能和延迟,数据中心场景下高性能、低延迟为主要需求,端口速率多在100Gbps以上,端到端延迟可控制在微秒级,而园区场景下性能要求相对适中,端口速率以千兆、万兆为主,延迟控制在毫秒级即可满足需求。
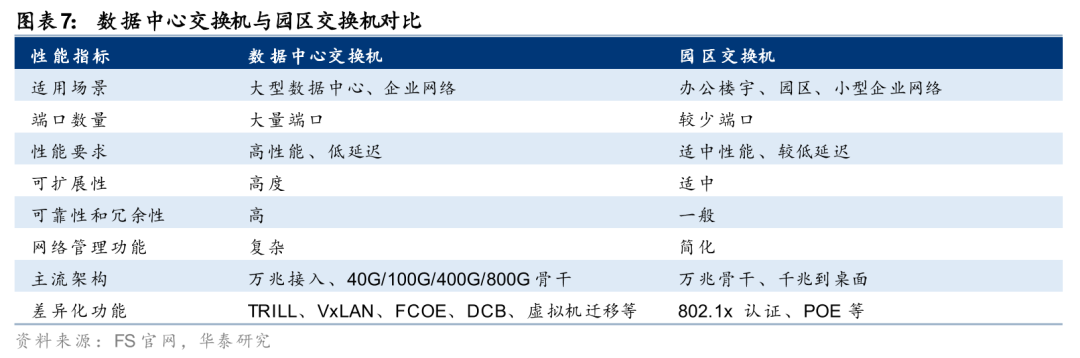
在数据中心交换机中,根据互联方式的不同,可进一步分为Scale up交换芯片和Scale out交换芯片。AI集群的互联结构主要包括Scale out和Scale up:1)Scale out指跨节点、跨服务器的分布式互联方式,主要通过以太网、InfiniBand等协议实现拓展,通过高速、大规模的组网架构来提升整体的算力规模,在Scale out网络中,交换芯片侧重于广域的大规模调度,单卡(网卡)通信带宽主要处于400Gbps至1.6Tbps级别,在时延层面,交换芯片单跳物理延迟通常在数百纳秒左右,而跨服务器的端到端通信时延则在10微秒级;2)Scale up指节点内部(如机柜内)以专用高带宽、低延迟互联协议将多颗XPU进行直连,例如NVLink、UB Switch、UALink等,从而提高单节点的算力效率。在Scale up网络中,交换芯片需支撑单颗 XPU 达到数 Tbps 至十余 Tbps(如NVLink5的1.8TB/s(14.4Tb/s)级别)的超高双向互联带宽,且端到端通信时延亦需压缩在1000纳秒以内。
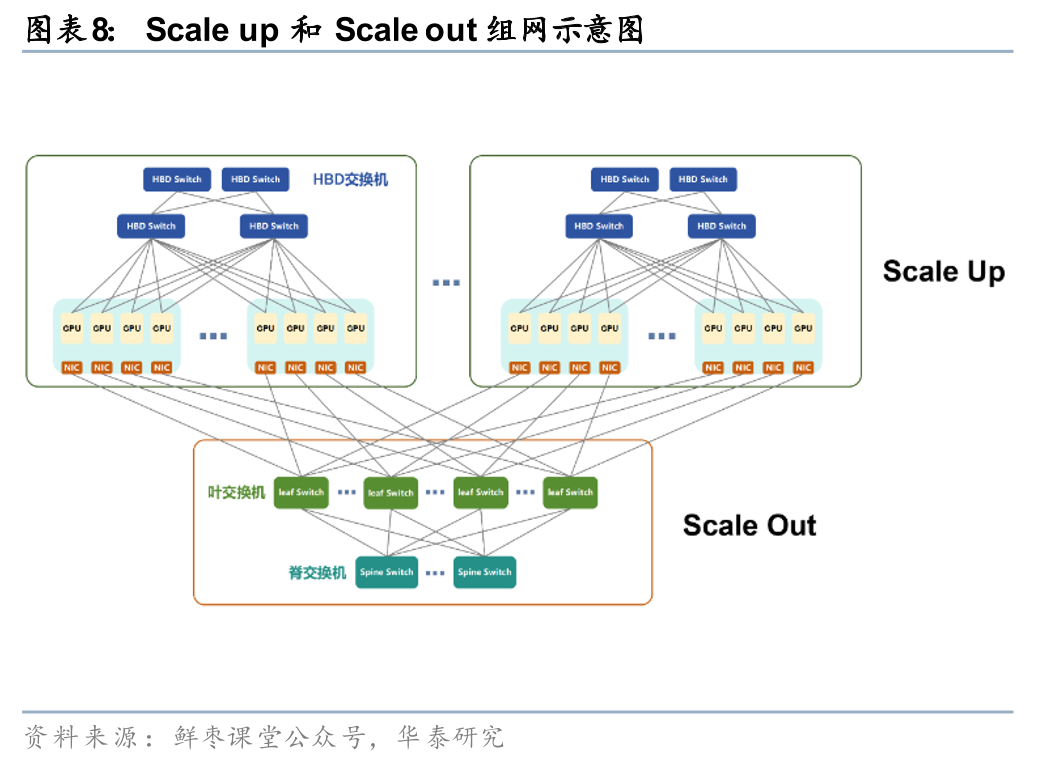
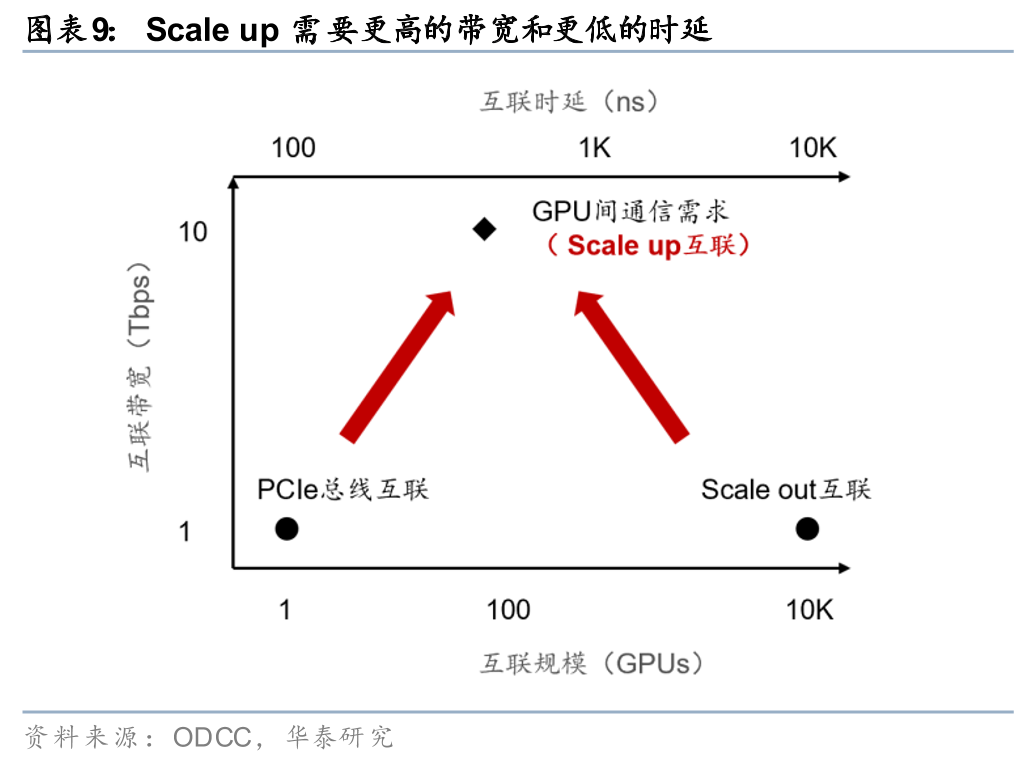
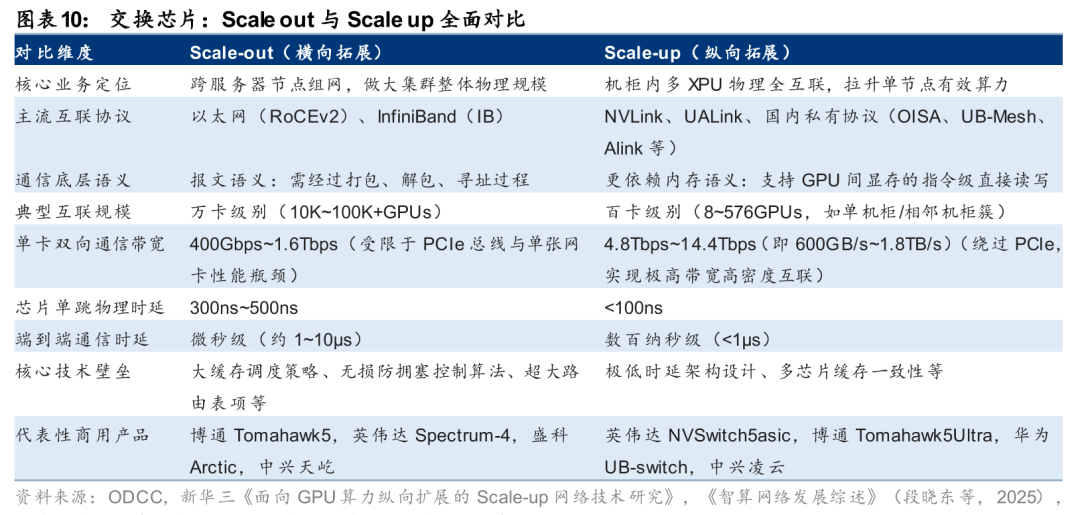
需求侧:AI&超节点带动技术升级,国内市场有望加速增长
需求:AI驱动全球加码算力,CSP 运营商资本开支持续积极
我们认为,交换机(及其核心交换芯片)有望同时受益于“训练端规模扩张”与“推理端流量增长”的双重需求共振,或将自26年起开启新一轮长周期的景气上行:
训练端:大模型参数持续演进,网络或将决定有效算力边界。随着AI大模型参数规模向十万亿级迈进(特别是MoE混合专家架构的逐步普及),且训练数据集规模持续攀升,分布式并行计算的通信复杂度显著提升。海量节点间频繁的参数交换与梯度同步,对网络的确定性时延、吞吐带宽及无损传输能力提出了更为严苛的要求。为了规避因网络拥塞导致的计算节点等待,亟需构建高带宽、低延迟的算力网络底座,以保障万亿级参数模型在超大规模集群上的持续高效迭代。
推理端:应用落地高并发量催生高速互联需求,超节点或为新趋势。随着大模型应用向多模态交互和复杂逻辑推理深度拓展,推理集群的并发请求量呈现快速增长态势。而面对海量的并发处理需求,超节点架构有望凭借极高的内部互联带宽与低延迟特性,有效缓解跨算力节点的通信瓶颈,从而显著提升单节点的综合算力利用率。因此我们看好,推理端“流量增长” “超节点渗透趋势”对于交换芯片需求的拉动。
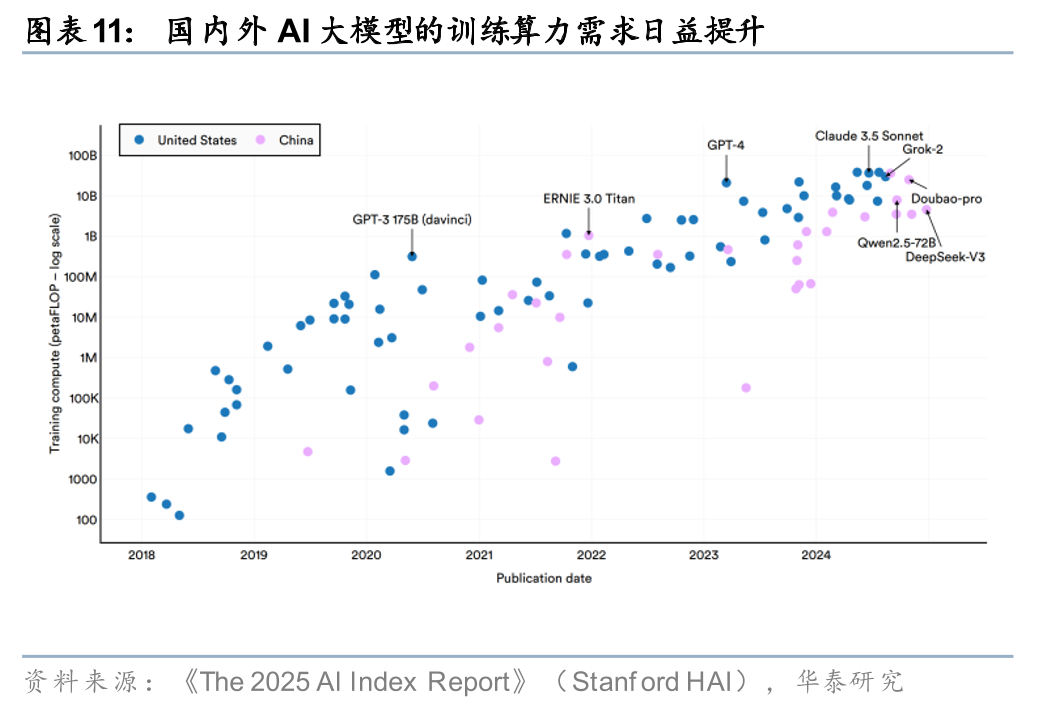
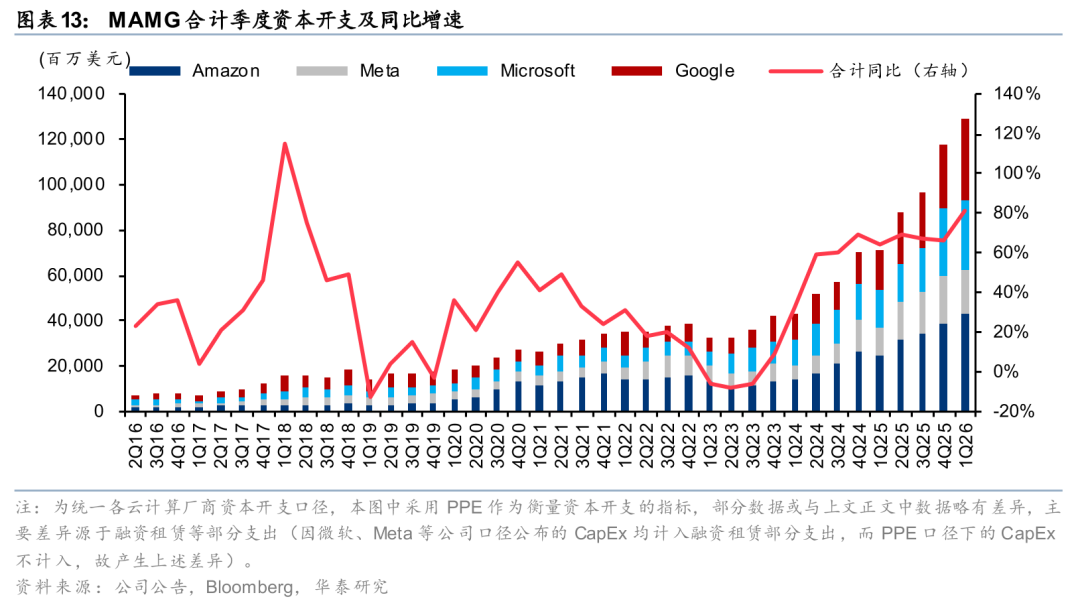
海外需求(参照):北美CSP资本开支延续高增趋势并对未来保持乐观指引,有望支撑AI基础设施建设的持续推进。2026年4月末,北美CSP公布1Q26业绩,1Q26 MAMG(微软、亚马逊、Meta、谷歌)合计资本开支同比提升81%至1287.81亿美元,再创历史新高,MAMG四家均对2026年的资本开支保持乐观并部分上修指引:1)微软新增全年指引1900亿美金,预计2026财年资本开支的同比增长率将高于2025财年;2)亚马逊计划在2026年全公司范围内投入约2000亿美元资本支出(本次维持预期),投资将主要集中在AWS部门;3)Meta上调2026 年资本支出指引至1250-1450亿美元(前值:1150-1350亿美元);4)谷歌上调2026年资本支出指引至1800-1900亿美元(前值:1750-1850亿美元),投资额将在年内逐步增加。英伟达于2025年8月的业绩会中判断,全球科技大厂对于AI基础设施的投入有望由2025年约6000亿美金增长至2030年的3-4万亿美金。
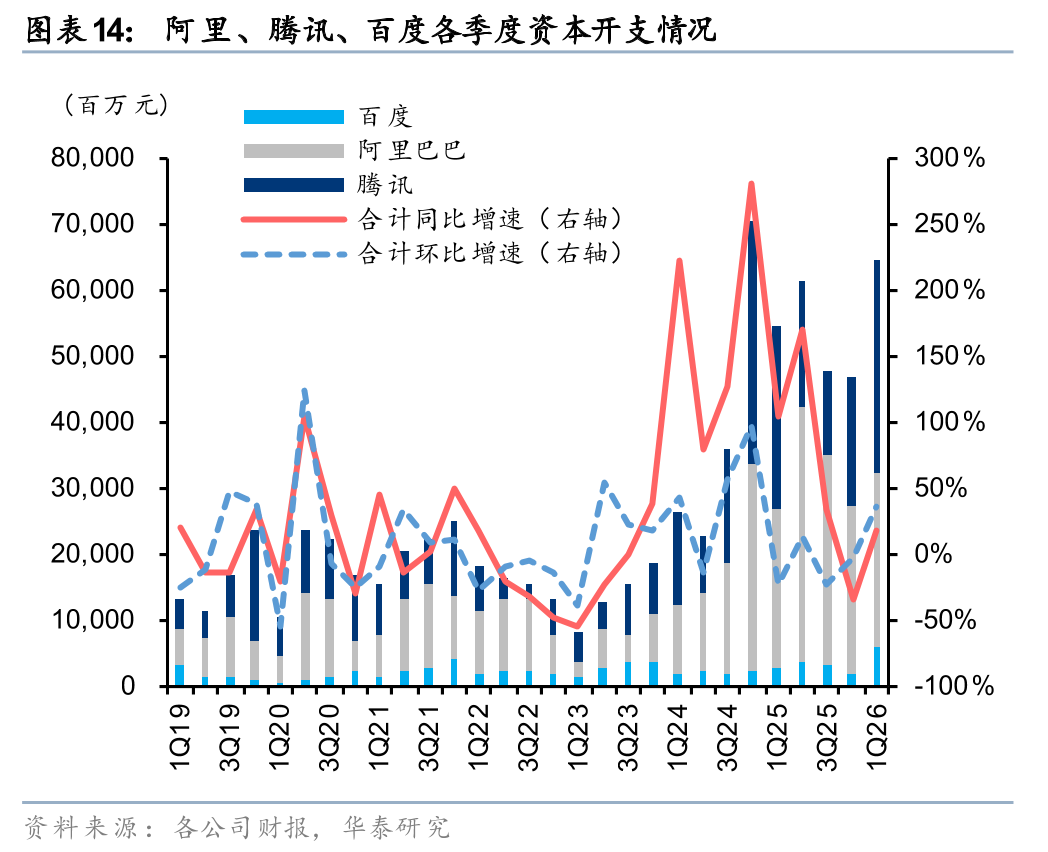
国内需求:BBAT继续推进AI投资,运营商持续加码算力。国内数通需求主要集中于大型互联网厂商和运营商:
互联网厂商:2025年阿里、腾讯、百度合计资本开支为2106.97亿元,同比提升36%,1Q26国内三大上市互联网厂商阿里、腾讯、百度合计资本开支为644.4亿元,同比增长19%,环比增长37%。针对2026年,互联网厂商均给予积极的AI投资指引:1)字节:根据财联社2026年5月9日报道,字节正在进一步加大对AI的投资力度,将上调2026年投入至2000亿元以上,较此前的初步计划增加了25%;2)阿里:根据阿里在1Q26业绩会中的表述,考虑到AI基础设施需求,公司未来的AI相关投入或远超此前提出的3年3800亿元规划,公司将始终坚定不移地持续AI投资;3)腾讯:腾讯在其1Q26业绩会中表示,公司此前已指引今年资本开支将高于去年,目前对此更加确认,并预计其资本开支将在下半年进一步增加,原因在于中国自研ASIC芯片的逐步供应;4)百度:根据百度4Q25业绩会,百度表示自23年3月以来百度在AI方面的累计投资已超过1000亿元,未来将继续保持这一投资强度。
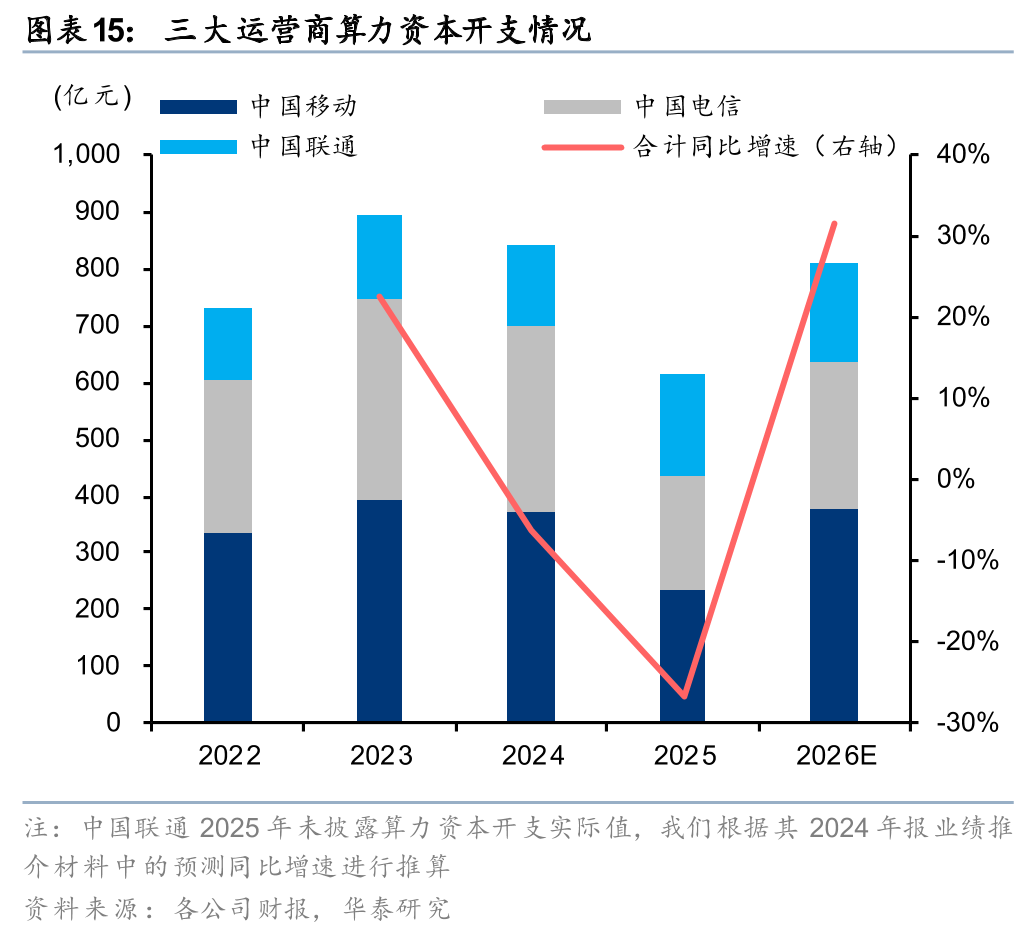
运营商:2025年中国移动、中国电信、中国联通三家合计算力资本开支约614亿元,同比-27%,主要系央企提质增效战略影响,2026年各家将继续优化资本开支结构,向算力建设倾斜,2026年三家合计算力资本开支预计值为809亿元,同比 32%:1)中国移动预计算力网络资本开支同比提升62.4%至378亿元;2)中国电信预计算力基础设施投资同比提升26%至256亿元;3)中国联通预计算力资本开支占25年总资本开支(公司预计500亿元)的35%以上,即175亿元以上。
发展趋势:看好交换芯片行业迎来高端化、“up”起量、国产化三重变革
趋势#1:交换芯片持续高端化,交换容量扩大、端口速率提升、时延降低
以数据中心网络Scale out和Scale up为划分,两种场景的交换芯片均往更大容量、更高的支持速率进行演进,分别来看:
Scale out:一方面,随着训练集群向十万卡量级演进,单台交换机需要能够直连更多的底层节点,以保证大型集群维持在高效的两层架构内,从而降低因跳转节点而产生的时延,因此交换芯片需要更大的交换容量;另一方面,随着新一代AI GPU计算能力与HBM内存带宽的跃升,单算力节点的数据吞吐速率也随之提升,为了避免网络传输成为制约单卡算力利用率的短板,GPU所配套的网卡正持续向高带宽升级(如800G→1.6T),这也将要求交换机(交换芯片)支持原生的高速率端口(如1.6T)。
Scale out主要分为InfiniBand和以太网两条技术路线:
InfiniBand协议方面,目前主要玩家为英伟达,最新代交换芯片支持800G端口速率,交换容量为28.8Tbps。2025年3月18日,英伟达在GTC大会上推出Quantum-X Photonics交换机,其交换芯片为Quantum-X800 ASIC,采用台积电4nm工艺封装,包含1070亿个晶体管,通过CPO技术集成6个光学子组件(每个光学子组件由3个基于COUPE技术的光引擎组成,每个引擎均可提供1.6Tbps的发送/接收吞吐量),交换容量28.8Tbps,且支持1.6 FLOPS的FP8 SHARP网络计算性能。Quantum-X Photonics交换机包含4颗Quantum-X800 ASIC(最终组成115.2Tbps),可提供144个800Gb/s InfiniBand端口。
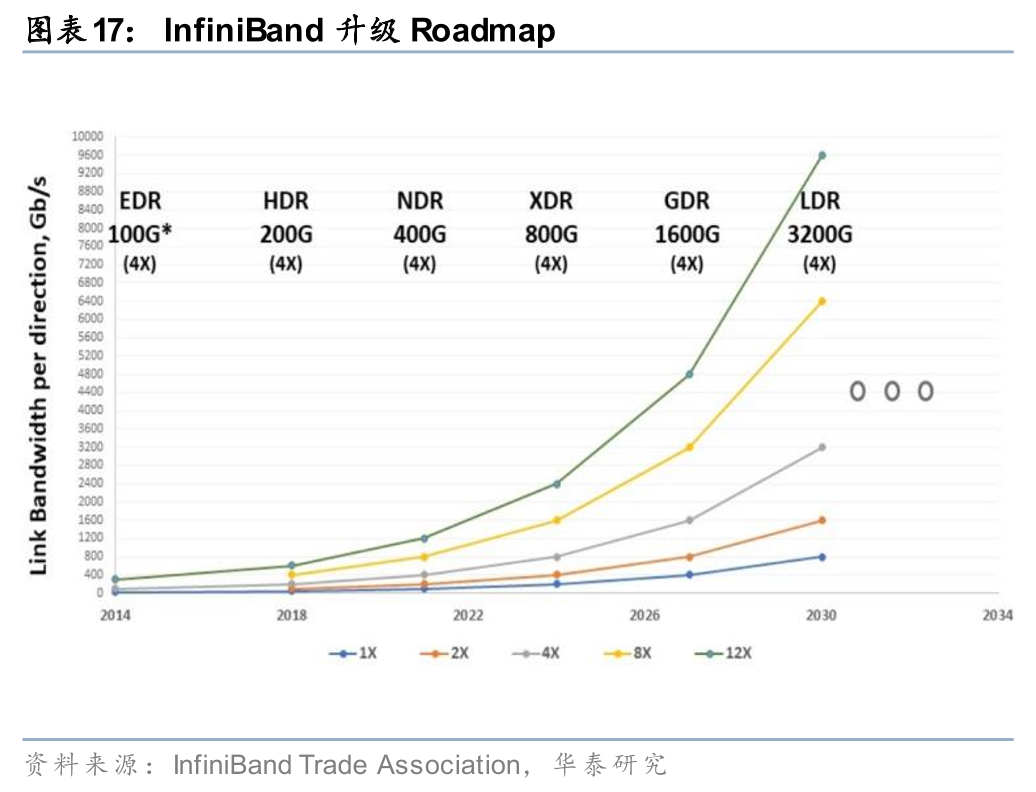
速率方面,从InfiniBand Roadmap来看,带宽有望从当前的800G XDR向2027年的1.6T GDR和2030年的3.2T LDR升级,反映市场对高带宽的需求将持续存在,从而推动技术迭代升级。

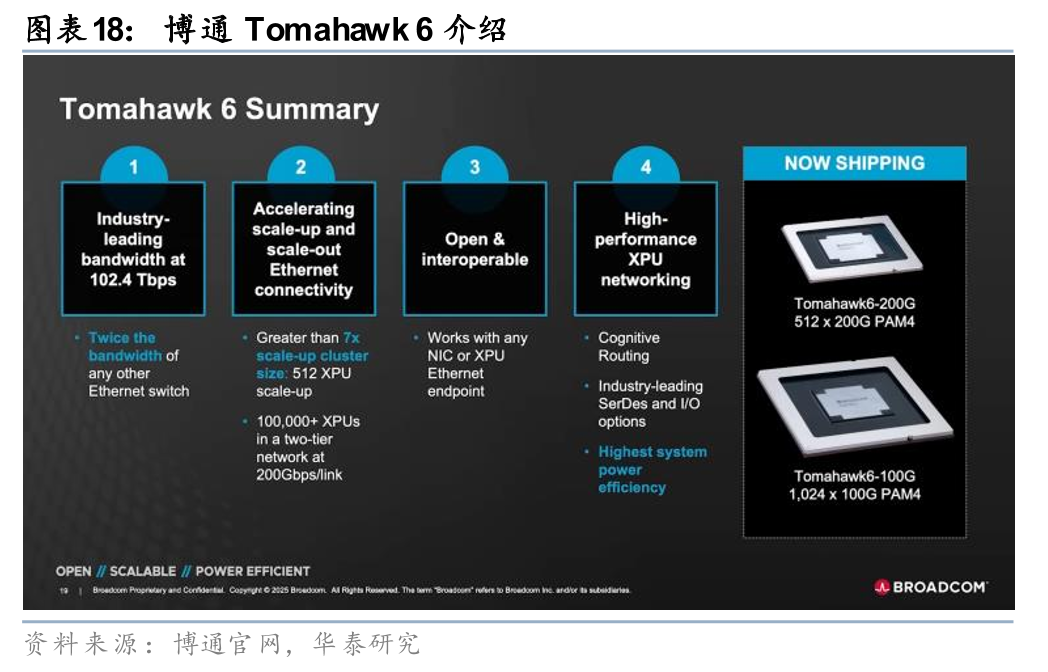
以太网协议方面,目前博通、英伟达和思科均推出各自102.4Tps交换容量的芯片方案,博通和思科最高可支持64个1.6TbE端口。博通于2025年6月3日发布最新代交换芯片Tomahawk 6,交换容量102.4T,最高可支持64个1.6TbE端口,采用3nm制程及CPO技术,有效降低成本并提升性能,可用于搭建512颗XPU的超节点(Scale up)以及十万卡集群(Scale out)。英伟达于2026年1月5日的CES 2026发布最新款以太网交换机Spectrum-6系列,其交换芯片Spectrum-6的交换容量同样为102.4Tbps,通过CPO技术将32个1.6Tb/s硅光光学引擎与交换芯片直接封装集成,包含一个交换芯片的SN6810交换机可支持128个800G端口。思科于2026年2月10日发布Silicon One G300交换芯片,采用台积电3nm工艺,交换容量达到102.4Tbps,最高可支持64个1.6T端口,专为千兆瓦级AI集群设计,相比上代产品G200和竞争产品,G300网络利用率提升33%,作业完成时间缩短28%。


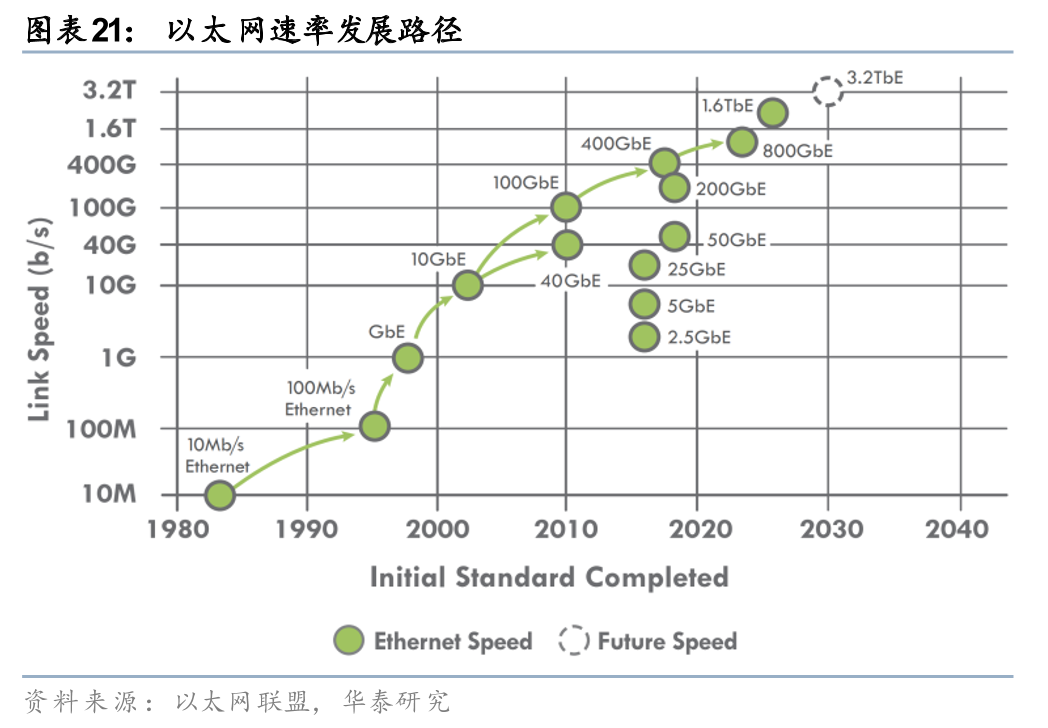
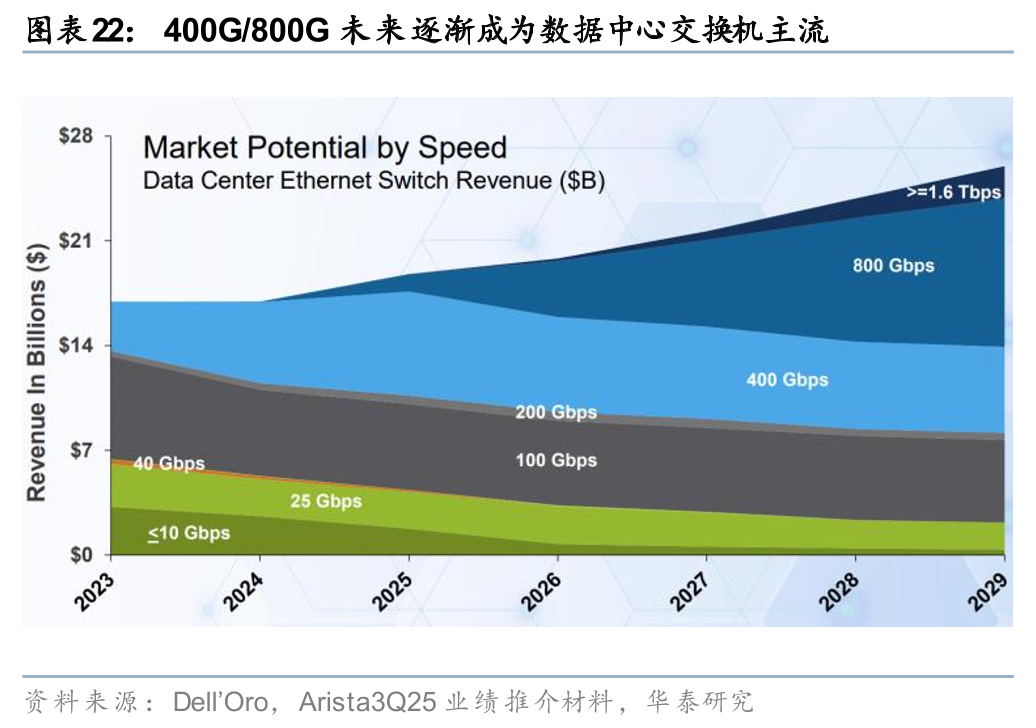
速率方面,从以太网路线图来看,目前最高支持1.6TbE,有望在2030年达到3.2TbE,主要通过提高物理通道波特率、增加并行通道数量和使用更高级调制技术三种方式实现。从实际应用情况来看,根据Dell’Oro在2025年7月的统计和预测,2026年以后400G/800G将逐渐成为数据中心交换机主流,26年400G/800G合计占比有望接近市场的一半,27年以后800G交换机占比将继续提升,成为第一大需求,届时也有望开始出现1.6T的市场需求,至29年高速数据中心交换机总市场有望超过240亿美元。
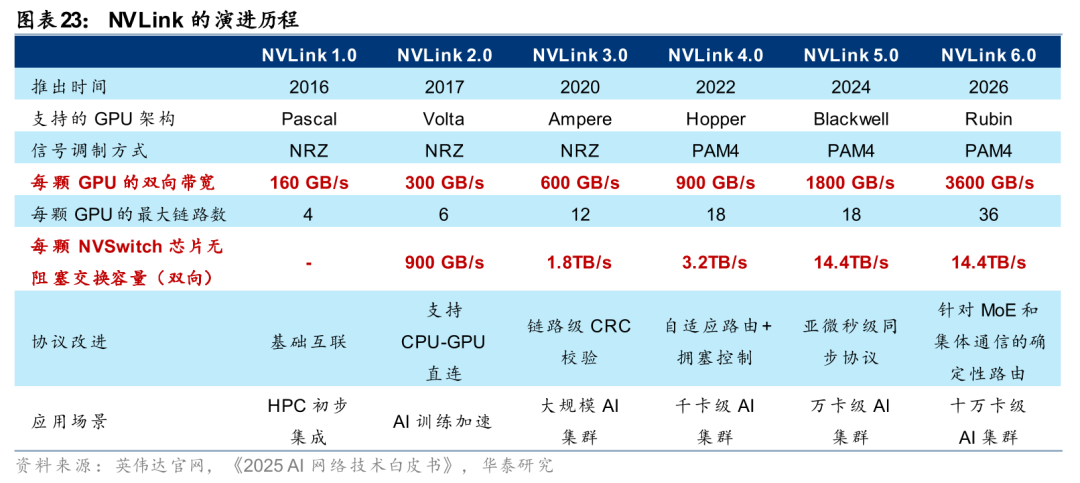
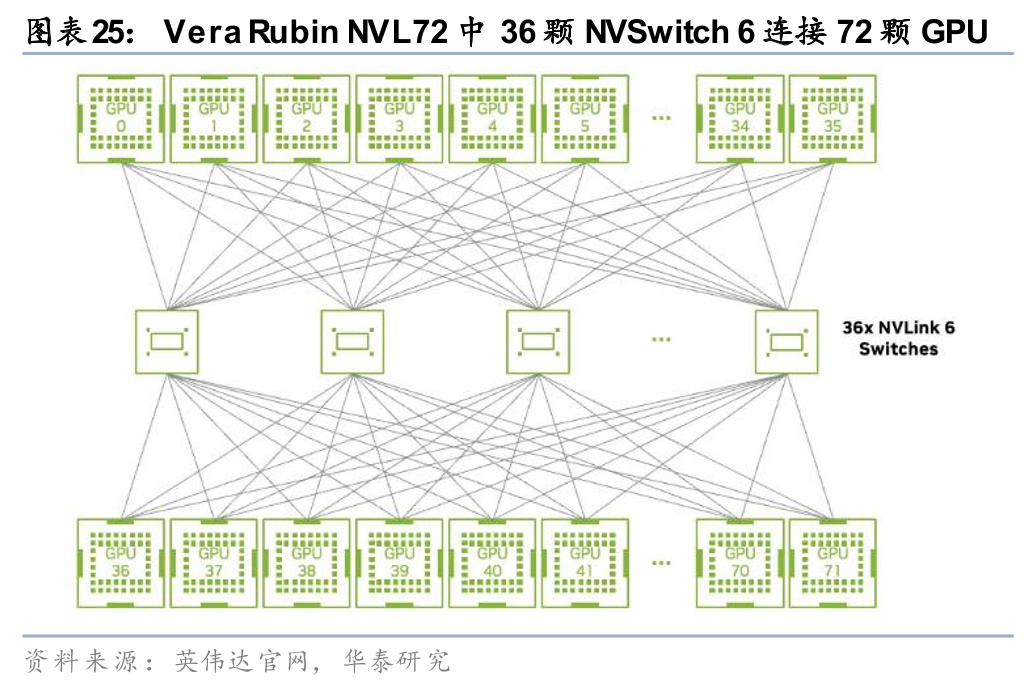
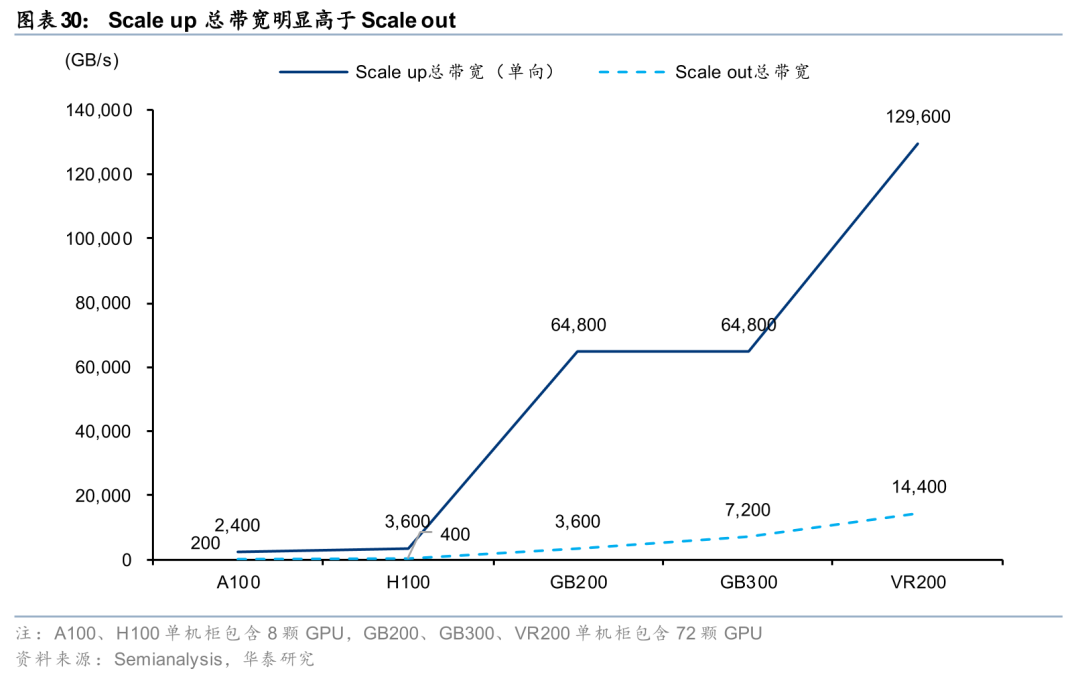
Scale up:以英伟达私有协议NVLink为例,英伟达2026年已发布第六代NVLink技术,GPU之间双向互连带宽达到3.6TB/s,单芯片无阻塞交换容量达14.4TB/s。英伟达于2024年3月的GTC大会上推出GB200 NVL72服务器,基于第五代NVLink技术实现内部72颗GPU的互联,是通过Scale up构建超节点的典型应用。2026年1月5日,英伟达在CES 2026上发布由六大核心组件构成的Vera Rubin NVL72服务器,其中第六代NVLink带宽相比上代翻倍达到双向3.6TB/s,单机柜总带宽达到259.2TB/s,而单机柜中包含36颗NVSwitch交换芯片,对应每颗芯片的交换容量为14.4TB/s(259.2*2/36,乘2为预留同等规模的向上端口)。回顾过去的迭代进程,NVLink/NVSwitch的组合基本保持了代际带宽翻倍的演进节奏。展望未来,我们认为,随着底层算力节点的性能持续提升、单机柜集群密度的增加,定制化的Scale up交换芯片或继续向高带宽、大交换容量以及低时延进行演进。

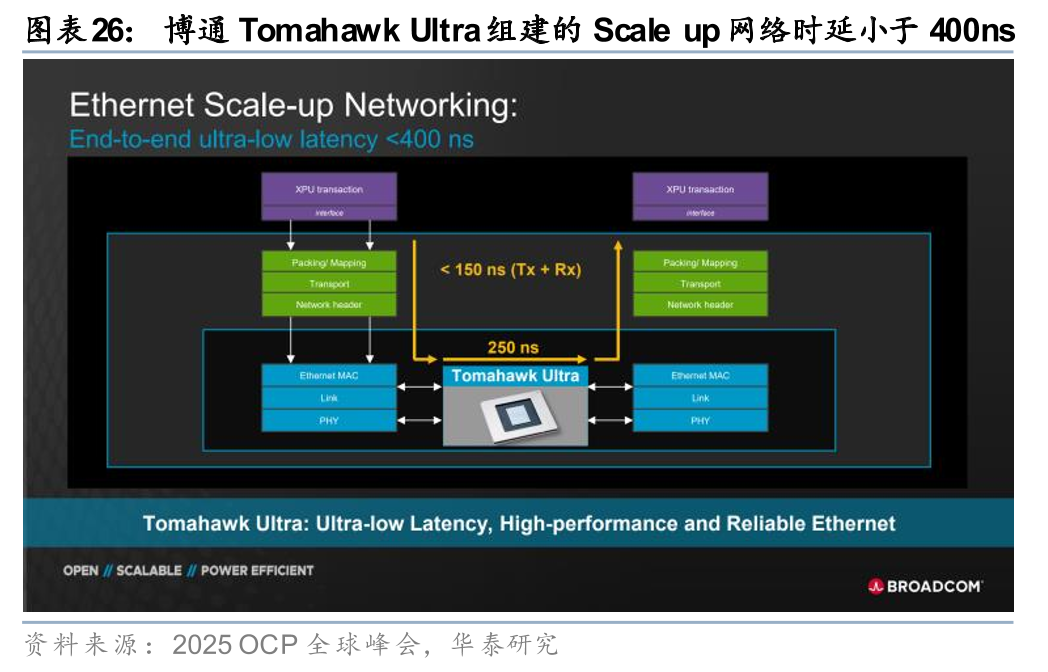
此外,超节点对于低时延有明确追求,Scale up交换芯片继续向“低时延”演进。Scale-up 网络的核心工程目标,是将机柜内数十甚至数百颗 GPU 聚合成一个具备统一共享内存的“超级节点”。在底层的内存语义通信模型下,跨 GPU 的数据交互如同访问本地显存。一旦网络出现较高的物理时延,高速运转的 GPU 计算核心便会被迫挂起以等待数据返回,进而导致整体集群的算力利用率显著下滑。因此,将端到端通信时延压降至纳秒级,是确保超大参数模型在超节点内高效迭代的物理前提,而交换芯片的处理时延则是端到端时延中的重要一环,未来或继续向更低的时延进行迭代。我们观察到,国内外巨头已着手降低Scale up交换芯片时延:1)博通以Tomahawk Ultra搭建Scale up网络时,端到端时延可控制在400ns以内,其中发送、接收过程的时延小于150ns,交换芯片处理时延约250ns,处于世界领先水平;2)中兴通讯自主研发凌云交换芯片,适配数十到数百颗芯片协同,将时延从过去的微秒级降至百纳秒级,满足海量数据传输;3)ETH-X超节点项目中,根据原型机首轮核心性能测试,一级网络单向传输时延小于900ns(约834.8ns),具体而言,事务层与传输层时延约157.3ns,光模块传输时延约220ns,交换芯片处理时延约466.5ns。
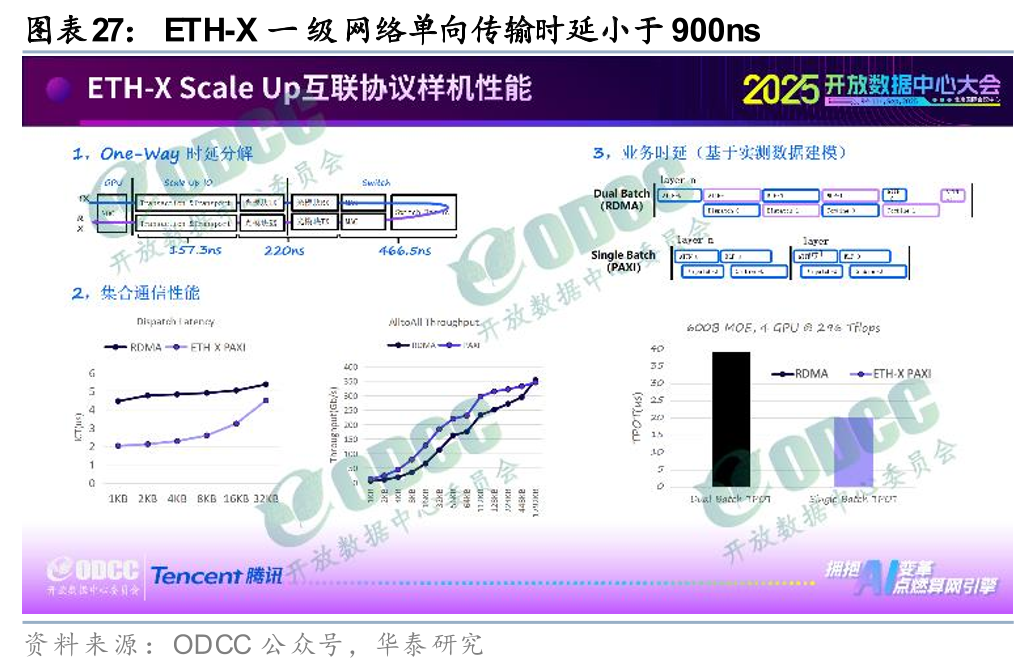
趋势#2:超节点趋势下Scale up交换芯片需求量大幅提升
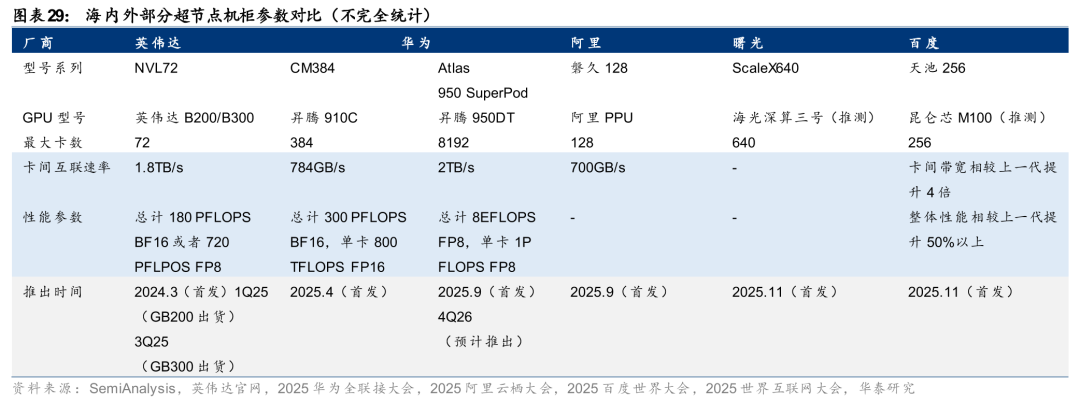
自2024年3月英伟达在GTC上发布GB200 NVL72超节点架构后,我们观察到2025年已有多个国内算力参与方发布自家超节点方案,如华为的CM384、阿里的磐久128、中科曙光的ScaleX640、百度的天池256、沐曦的耀龙S8000 G2等。
我们认为,超节点是国产算力的破局之道——多卡“团战”或为国产卡弥补与海外先进卡算力差距的必由之路。面对国内“单卡算力有差距”、“单位算力成本更高”两大困局,我国选取“超节点”这一路径,超节点通过多卡协同,依托我国领先的通信技术及工程实现能力,有望在集群层面实现持平甚至赶超海外超节点的性能,同时亦能通过机柜级/系统级架构提高每单位算力的资本效率。例如,根据SemiAnalysis,华为910C的CM384超节点便以5.3倍于英伟达GB200 NVL72的卡数,实现了1.7倍于NVL72的算力性能;曙光的ScaleX640通过640张GPU堆叠,亦能实现超600 PFLOPS算力,比肩国际先进集群水平。我们认为,自2H25开始,海外GPU对华供应始终存在不确定性,而国产GPU正在性能、良率、量产能力上逐步突破,在国产卡算力性能仍弱于海外先进卡的背景下,为实现高性能的训练与推理,国产超节点的需求有望持续涌现,目前我们已看到来自CSP厂商、算力芯片厂商、ICT厂商等不同主体推出的超节点样品,我们判断2026年或为国产超节点放量的元年。

Scale up互联距离更短、传输效率更高,符合AI模型大规模计算的需求,总网络带宽明显高于Scale out网络。虽然Scale out可以持续扩展规模,但其跨节点通信延迟较高、带宽受限。随着 AI 模型参数规模不断膨胀,单纯依赖跨节点的Scale out会显著拖累整体计算效率,而超节点的创新性在于强化 Scale up,通过突破“单机八卡”的物理边界,将Scale up拓展至整机柜级别,以更高密度的连接实现 64 卡、128 卡乃至更大规模的高带宽、低延迟互联,从而有效支撑模型训练、推理时的并行计算需求。因此,Scale up场景下互联带宽更大,以Vera Rubin NVL72为例,Scale up总带宽(单向)为129.6TB/s,Scale out总带宽为14.4TB/s,前者为后者的9倍。
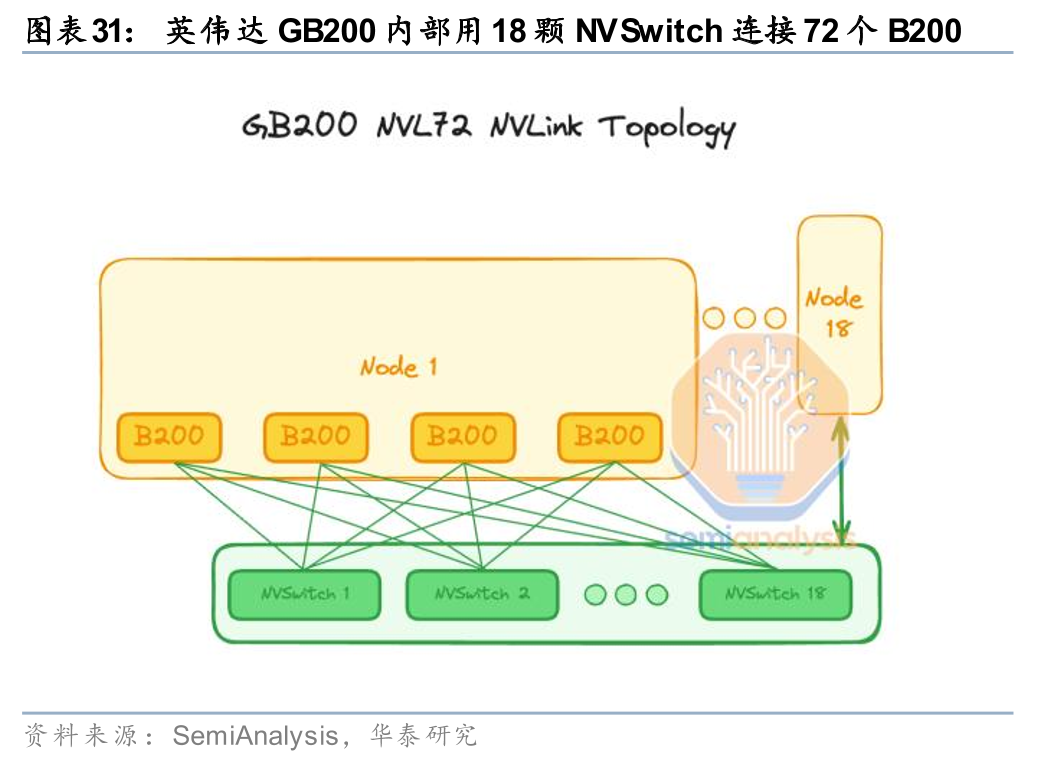
关于交换芯片与GPU的配比,我们分Scale up和Scale out来看:
Scale Up是超节点的核心增量环节,对国内算力参与方来说,单卡算力差距或可部分由“运力”(网络)进行弥补,对比华为CM384和英伟达NVL72,前者Scale up交换芯片与GPU配比高于后者(25%)。根据冯诺依曼计算机体系架构,计算、存储、网络三要素必须保持系统级平衡,即国产超节点不能仅堆GPU算力卡而不增强网络。我们认为,基于国产卡与海外卡的算力差距,若需在网络上进行补齐,则国产超节点中Scale up交换芯片与GPU的比例或高于海外。举例来看,海外方面,英伟达推出的GB200 NVL72内使用18颗NVSwitch4 ASIC将72颗B200 GPU进行 Scale up 互联,即交换芯片:GPU=18:72=1:4。国内方面,华为CM384的单节点中8颗NPU通过7颗UB Switch 实现卡间互联,因此交换芯片:NPU=7:8。从二者算力比较来看,尽管昇腾910C的单芯片算力仅为GB200的 1/3,但CM384、GB200 NVL72的BF16稠密算力分别为300、180PFLOPS,前者几乎是后者的两倍,可见单卡算力的差距可以通过Scale up等网络进行弥补,随着机柜式服务器成为未来发展趋势,机柜内部的Scale up交换网络格外重要。
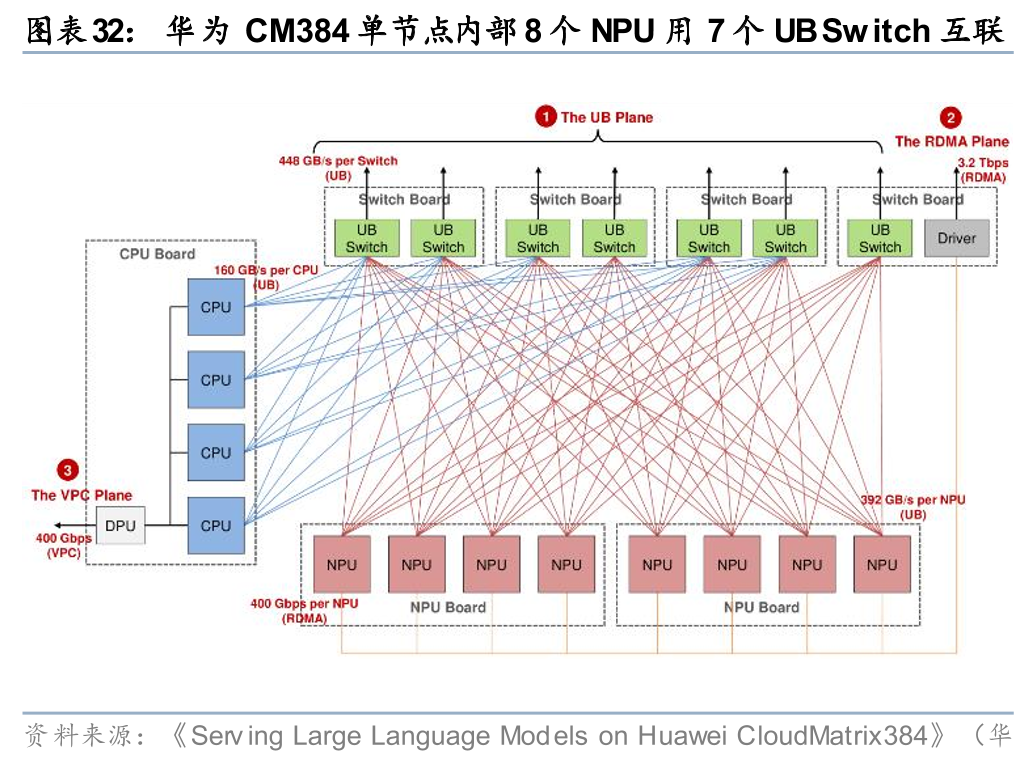
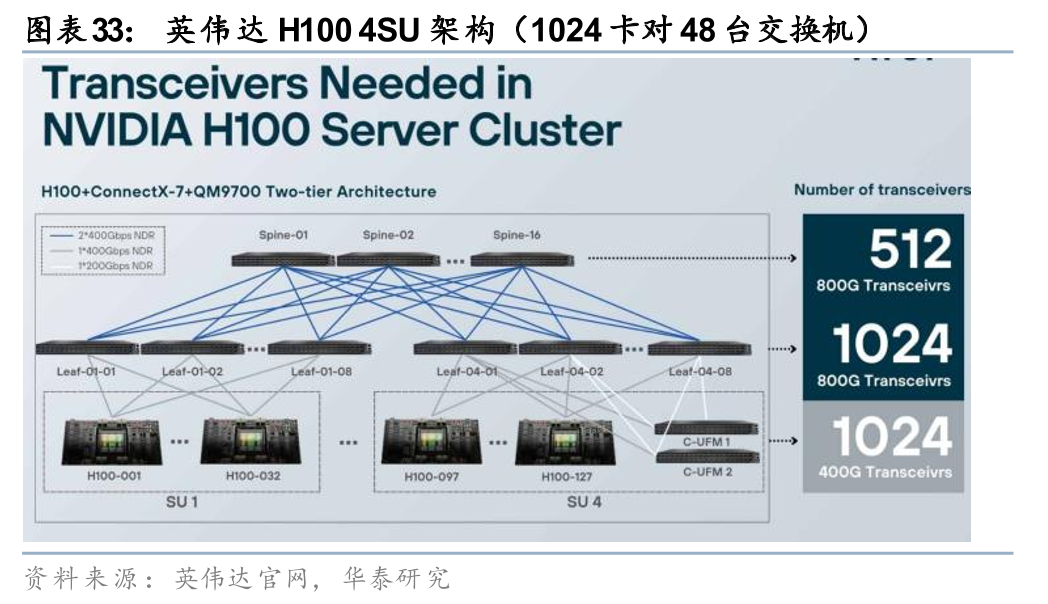
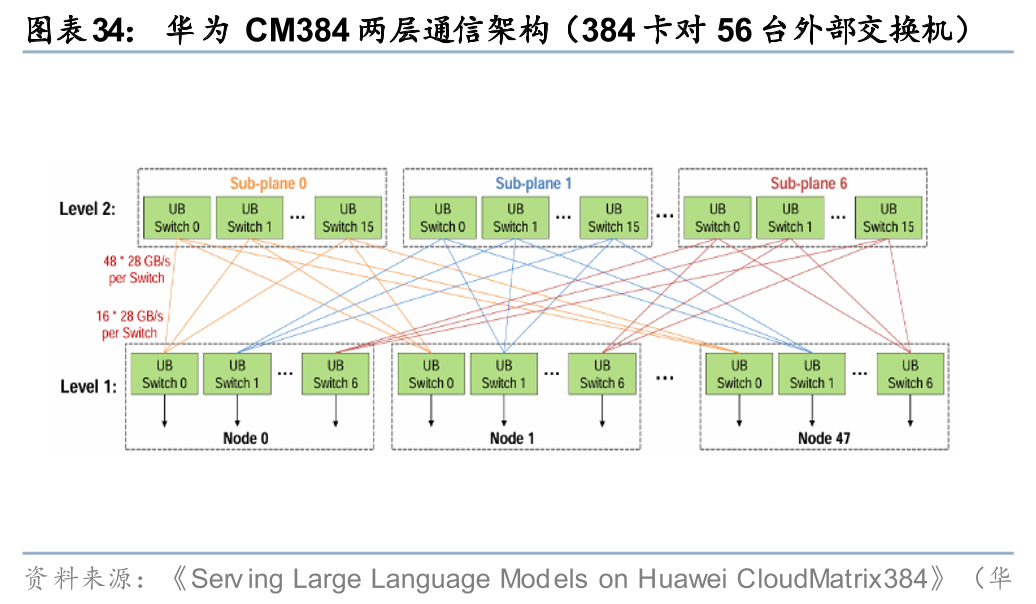
Scale out方面,经典H100集群中的交换机与GPU配比约为5%,网络架构在国产卡集群中格外重要,配比或将更高。我们以英伟达H100的4SU集群和华为CM384集群组网为例:1)在英伟达4SU H100集群中,一个SU节点为32台8卡H100服务器,4SU即1024张卡,从外部交换机来看,1024张H100用到了16台Spine交换机和32台Leaf交换机(均为25.6T),其交换机与GPU的配比约为5%(48/1024),交换芯片与GPU配比亦约为5%;2)在华为CM384集群中,仅看位于Level 2层级的外部交换机,一共有112颗UB Switch交换芯片,在华为的总线柜中2颗交换芯片形成一台38.4T交换机,即56台交换机,其交换机与GPU的配比约为14.6%(56/384),若将交换芯片换算为25.6T,则等效的交换芯片与GPU配比约为22%。综上,我们看到国产卡集群中用到了比H100集群更高比例的交换机配置,因而我们认为,在2026年国产卡起量的背景下,为弥补计算性能的落后,国产卡所搭配的交换机配比或提升。
趋势#3:海外限制与国内政策激励下,交换芯片国产化率或加速提升
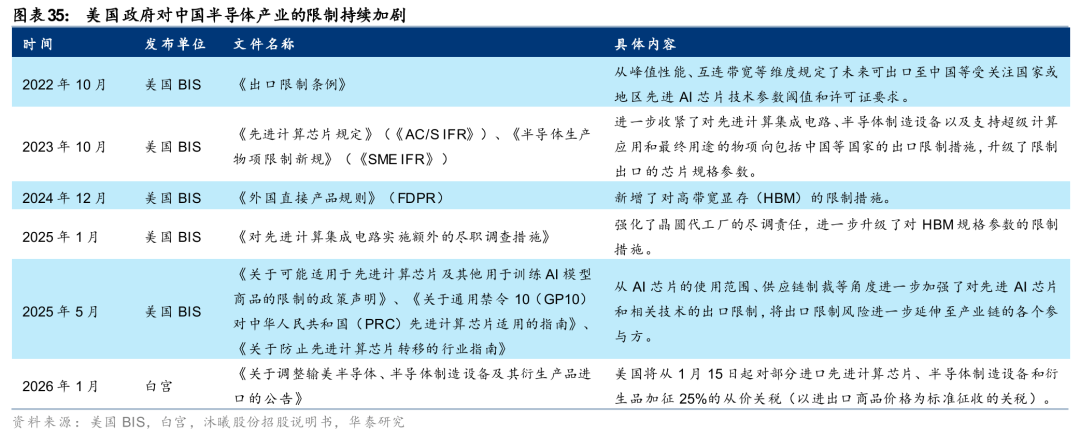
AI是中美科技博弈的关键领域,近年来美国采取多项措施对我国半导体产业发展进行限制。2019年以来,美国先后将海光信息、寒武纪、盛科通信、摩尔线程等国内头部 AI 芯片企业列入“实体清单”。2022年10月,美国商务部工业与安全局(BIS)发布了《出口管制条例》,从峰值性能、互连带宽等维度规定了未来可出口至中国等受关注国家或地区先进 AI 芯片技术参数的阈值和许可证要求。2025年5月,美国 BIS 发布《关于可能适用于先进计算芯片及其他用于训练 AI 模型商品的管制的政策声明》等,从 AI 芯片的使用范围、供应链制裁等角度进一步加强了对先进 AI芯片和相关技术的出口管制,将出口管制风险进一步延伸至产业链的各个参与方。可以看到,美国对我国半导体产业的限制在广度(从GPU到HBM、上游核心零部件,覆盖范围逐步扩大)和深度(通过修订FDPR、实体清单等,限制对象从单纯的企业实体拓展至技术标准、人才流动)上都有了明显提升,而地缘政治冲突的长期存在推动了我国国产芯片的发展和应用,较大的供给缺口使得客户与国产厂商建立更紧密的合作关系。
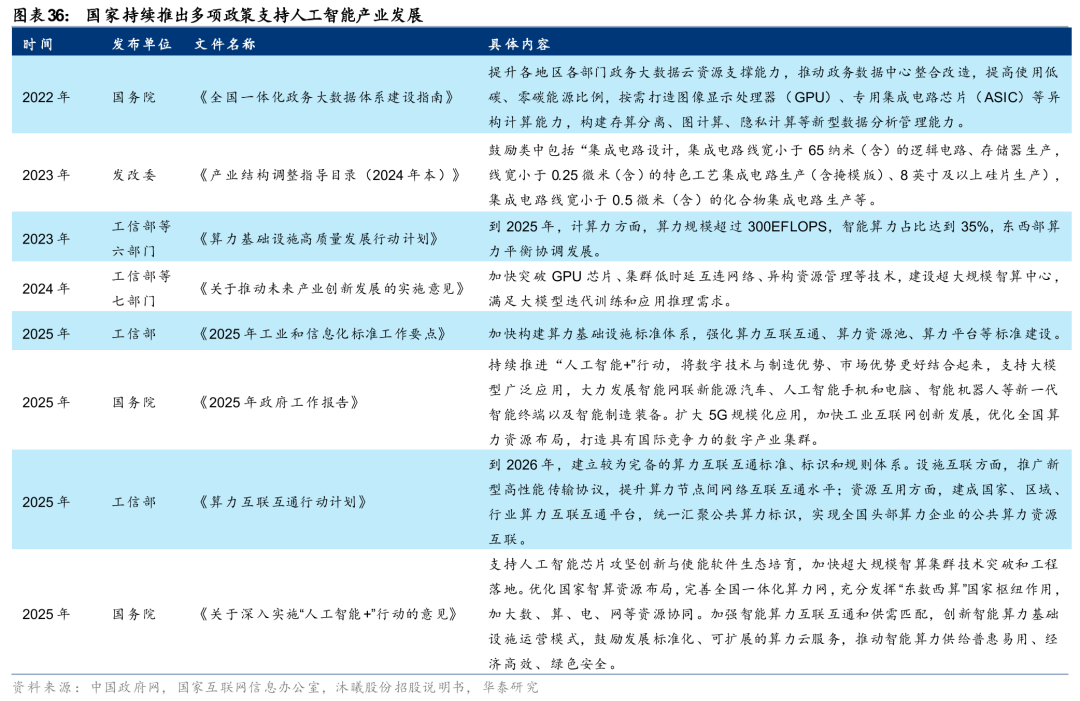
国家密集出台多项扶持政策,为人工智能产业链发展提供有力保障。2022年,国务院出台《“十四五”数字经济发展规划》,提出要瞄准集成电路等战略性、前瞻性领域,完善集成电路等重点产业供应链体系。2023年,工信部等六部门发布《算力基础设施高质量发展行动计划》,计划到2025年,算力规模超过300EFLOPS,智能算力占比达到35%。2024年,工信部等七部门发布《关于推动未来产业创新发展的实施意见》,提出加快突破GPU芯片、集群低时延互连网络、异构资源管理等技术,建设超大规模智算中心。2025年8月,国务院出台《关于深入实施“人工智能 ”行动的意见》,提出要深入实施“人工智能 ”行动,大力推进人工智能规模化商业化应用,推动人工智能赋能千行百业,加快智能算力、数据中心等数字基础设施建设。国家政策的密集出台,为我国自主可控产业链的构建、本土厂商的发展塑造了良好环境,相关厂商有望迎来新机遇。
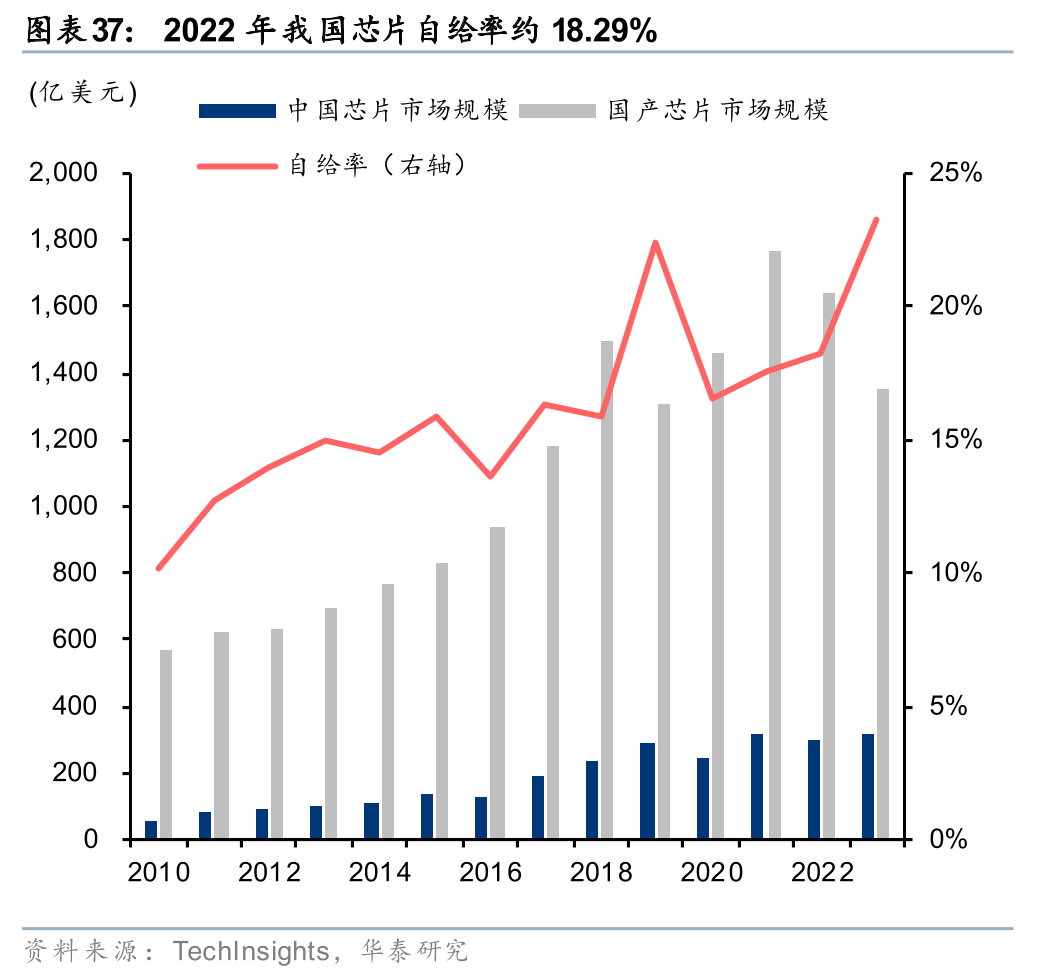
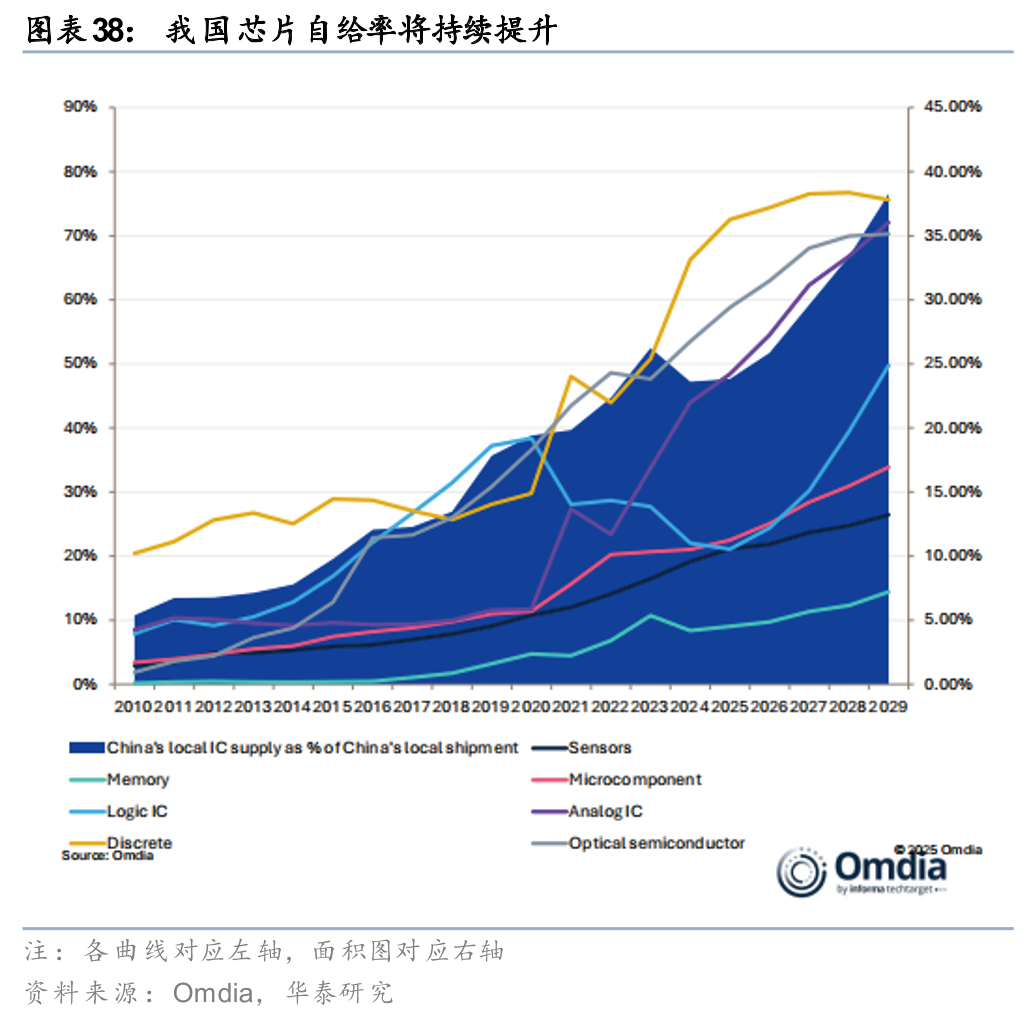
我国芯片自给率有待进一步提升,本土厂商的替代空间广阔。在AI、5G通信及新能源汽车等新兴产业的驱动下,我国的芯片需求快速增长,但受制于底层架构、核心设备和高端制造工艺等壁垒,目前我国芯片自给率仍处于比较低的水平,结构性供需矛盾突出,高端逻辑芯片、存储芯片及先进封装设备长期高度依赖进口。据TechInsights数据,2022年我国芯片市场规模约1640亿美元,其中国产芯片市场规模为300亿美元,自给率仅为18.29%。展望未来,随着我国强化重大技术装备攻关、加快解决“卡脖子”难题,芯片自给率或将持续提升。据Omdia预测,我国芯片自给率有望从2010年的10%出头提升至2029年的接近40%,细分品类上,我国目前分立器件、光电器件、模拟芯片的自给率已经提升至较高水平,有一定能力实现自主可控,而逻辑芯片、存储芯片、微元件的自给率仍有待提高。
国内头部交换芯片厂商自研程度日益提高,技术实力有望逐步追赶海外。我们认为,国内头部交换芯片厂商芯片设计能力、自研率均有所提高,未来可缓解外部供应的不确定性,为国内运营商、互联网厂商提供更具性价比、更本土化的网络解决方案。
如何看待交换芯片的国产化节奏?——市场亦关注交换芯片国产化的时间节奏,结合产业上下游发展规律,我们认为国产交换芯片在不同客户、不同场景的导入节奏存在显著差异:
1)政企与信创客户:需求偏中低端,国产化稳步推进。我们认为,在党政军及金融、能源等关键行业的园区及智算中心网络中,对网络带宽与时延的要求相对互联网厂商较温和,但对供应链安全要求较高,该类型客户是国产交换芯片高确定性、可快速推进的客户;
2)运营商客户:需求偏中高端,生态联盟加速国产芯片落地。运营商的算力网络建设受政策指引较为明确,未来或对中高端交换芯片有较大的集采需求。目前,国内运营商正积极通过开放标准和生态联盟推动国产芯片落地:a.在Scale out领域,中国移动牵头推进GSE(全调度以太网)计划,曾于24年9月招募合作伙伴欲完成对51.2T GSE交换芯片的开发;b.在Scale up领域,中国移动推出了OISA开放标准,联合国内交换芯片(盛科、中兴、云合智网)与自研GPU厂商共同参与卡间互联的生态建设。我们认为,运营商带动的深度生态配合模式有望为国产芯片提供更多的现网应用机会,加速产品迭代。
3)互联网厂商:需求偏高端,Scale out与Scale up领域的国产化节奏存在分化。互联网厂商对于AI训推中的网络吞吐与时延要求较高。我们认为其在不同网络架构下的国产化推进节奏将有所区别:I. Scale out领域,国产化或将按正常节奏稳步推进。我们认为,当前互联网厂商的商业采购主要由市场化原则主导,而由于国产高端芯片在商业化初期尚需跨越产能爬坡和研发投入的转化周期,因而我们判断该领域国产交换芯片导入将是一个正常渐进的过程。II.Scale up领域,国产化进展有望更快。超节点网络具有较高的复杂性,需要交换芯片与GPU厂商进行深度的底层适配。相比于海外巨头,国产交换芯片厂商更具配合意愿和本土化优势,或将加速导入进程。

另一方面,我们认为国产化推进仍面临若干现实难点,需要客观看待:
1)供应链认证周期长,通常需1-2年甚至更长时间。交换机作为数据中心网络的交通枢纽,其稳定性关系到整个集群的可用性,试错成本较高。这意味着即便产品性能达到一定水准,真正实现规模商业化出货仍需较长的市场导入期,给本土厂商带来资金周转与订单落地节奏的不确定性。
2)SerDes IP(串行/解串器)作为决定交换芯片物理带宽上限的核心技术,自主研发难度较高。目前国内厂商在112Gbps SerDes领域已取得突破(如中兴微相关产品),但面向支撑1.6T端口的下一代224Gbps乃至更高速率,挑战依然严峻。一方面,完全自主研发需要长期的技术积累与流片试错周期;另一方面,若依赖向海外主流IP供应商(如Synopsys、Cadence)引进授权,则面临潜在的供应链限制风险。因此底层高速IP的供给情况,或将影响高端交换芯片向更高端口速率演进的节奏。
3)Scale up领域协议尚未统一,生态适配面临较高成本。在跨机柜的 Scale out 网络中,以太网标准相对成熟;而在Scale-Up互联赛道,目前尚未形成统一的开放协议标准,各主要参与方推进不同协议:博通主导SUE协议、华为推进UB Switch协议、阿里主推ALink协议、海光等也有自有互联协议。协议差异化导致国产交换芯片厂商在覆盖多客户时,需针对不同生态分别进行协议栈适配与软件驱动开发,或将增加厂商的研发和维护成本。中长期看,行业有望向以太网、UALink等少数主流开放标准收敛,但在此之前,生态兼容或为交换芯片厂商带来额外的成本。
空间:预计28年国产Scale out/up交换芯片市场分别为113/129亿元
我们将数据中心交换芯片分为Scale out和Scale up两个场景,分别匡算其市场空间:
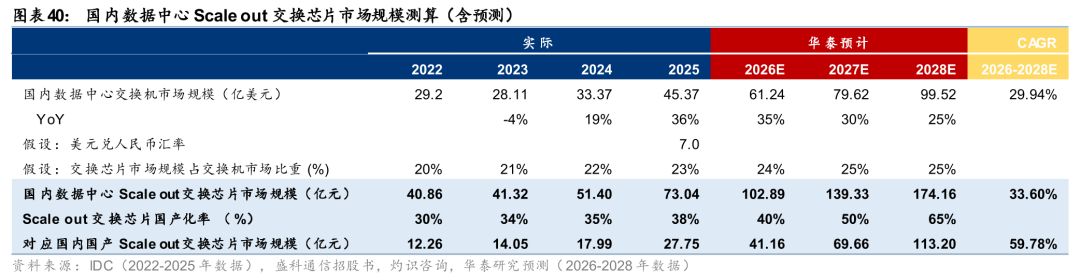
Scale out:我们预计到28年我国数据中心Scale out交换芯片市场可达174亿元,26-28E CAGR为34%;届时预计国产化率达到65%,对应国产Scale out交换芯片市场达113亿元,26-28E CAGR为60%。参考盛科通信招股书援引的灼识咨询2020年数据,2020年全球以太网交换机市场规模/以太网交换芯片市场规模分别为1807亿元/368亿元,因此交换芯片市场规模大致为交换机市场规模的 20%(亦可通过交换机厂商毛利率和交换芯片占BOM成本比例简单推导而出)。根据IDC数据,2025年我国数据中心交换机市场规模为45.37亿美元(同比 36%),我们假设2026/2027/2028年国内数据中心交换机市场增速分别为35%/30%/25%,则2026、2027、2028年国内数据中心交换机市场规模预计分别为61.24/79.62/99.52亿美元。假设美元兑人民币汇率为7.0,则2026/2027/2028年国内数据中心Scale out交换芯片市场规模分别为103/139/174亿元,由于海外芯片供应存在不确定性,未来交换芯片等关键芯片的国产化要求或提升,我们预计数据中心交换芯片国产化率由2022年的30%提升至2026/2027/2028年的40%/50%/65%,即对应2026/2027/2028年国内国产数据中心Scale out交换芯片市场规模分别为41.16/69.66/113.20亿元,2026E-2028E CAGR为59.78%。
Scale up:我们预计到28年我国数据中心Scale up交换芯片市场可达172亿元,26-28E CAGR为231%;届时预计国产化率达到75%,对应国产Scale up交换芯片市场达129亿元,26-28E CAGR为212%。据IDC数据,2024年我国AI芯片出货量超过270万颗,其中英伟达约190万颗,占比约70%;2025年我国AI芯片出货量400万颗,其中英伟达、国产芯片分别约220、165万颗,占比分别为55%、41%,出于审慎考虑,我们根据以上数据合理预估2025年我国国产AI芯片约150万颗。随着国产AI芯片性能提升、产能扩充,我们预计2026/2027/2028年国产卡出货量分别同比增长65%/50%/40%至约248/371/520万颗,由于技术限制,国产超节点架构均由国产AI芯片设计,故暂不考虑英伟达GPU在国内的出货量。随着华为、大型CSP等相继推出各自的超节点方案,且超节点架构有助于从系统层面提升整体算力效率,我们判断2026年或将是国产超节点密集出货的元年,且未来渗透率将逐步提升,预计2026/2027/2028年将分别有25%/35%/45%的AI芯片用于构建超节点架构。
参考各厂商的超节点架构,Scale up交换芯片与AI芯片的配比按30%计算。我们假设Scale up交换芯片的2026/2027/2028年平均价格分别为3000/3300/3500美元,主要系产品迭代带来的价格上升;假设美元兑人民币汇率为7.0。综上,我们预计2026-2028年国内Scale up交换芯片市场规模分别为38.98/90.05/171.91亿元。我们认为国产交换芯片厂商或更具备与国内CSP厂商共建网络生态的意愿,预计Scale up交换芯片的国产化率将高于Scale out交换芯片,故预计2026/2027/2028年Scale up交换芯片国产化率分别为50%/65%/75%,对应2026/2027/2028年国内国产Scale up交换芯片市场规模分别为19.49/58.53/128.93亿元,2026E-2028E CAGR为211.82%。
供给侧:交换芯片市场高度集中,国产厂商亟待破局
产业全景:交换芯片生产商位于交换机产业链上游关键环节
交换芯片处于交换机产业链上游关键环节。从产业链看:1)上游为交换机的各类组件,包括交换芯片、CPU、PHY、PCB等,其中交换芯片可分为自用和商用两类,自用芯片由制造商自主设计并用于其交换机产品,较少单独对外销售芯片;商用芯片即由制造商完成设计后直接对外销售;2)中游为交换机的整机生产,代工制造商通过代工、与品牌商合作、ODM等形式交付产品,品牌商既有软硬件捆绑的传统品牌交换机,亦有软硬件解耦(商用硬件 开放操作系统)的白盒交换机,白盒交换机具备灵活、高效、可编程等优势,逐步成为主流;3)下游为终端客户,云厂商/互联网厂商通过数据中心交换机构建大型数据中心,运营商将其用于城域网、承建及内部管理等,金融、政府等其他行业客户用于搭建企业网等。
产业格局:博通为全球市场龙头,盛科通信等积极提升国内份额
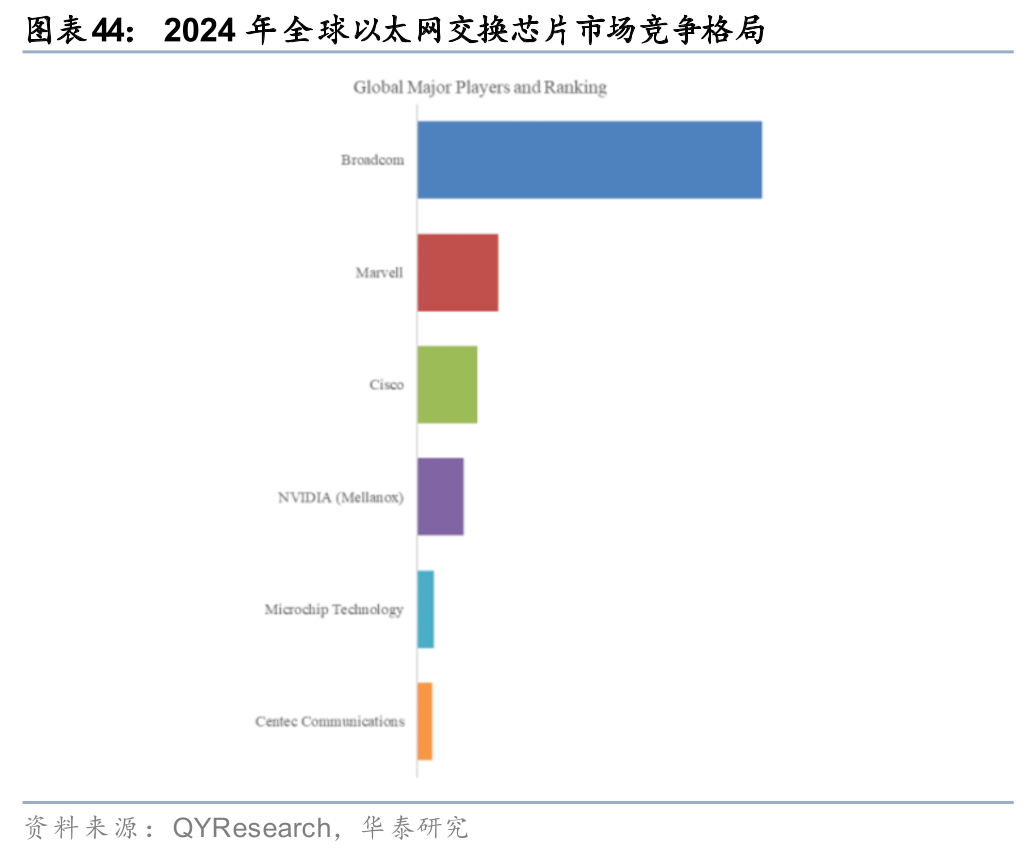
全球格局:2024年全球以太网交换芯片市场CR3达77.14%,博通占据龙头地位,未来商用厂商占比或进一步提升。据QYResearch数据,全球范围内以太网交换芯片市场高度集中,2024年博通、Marvell、思科的市占率分别为54.59%、12.95%、9.60%,CR3达到77.14%,此外英伟达(Mellanox)市场份额约7-8%,Microchip和盛科的市场份额稳定但较为有限,合计约占5%,上述企业中,博通、Marvell、盛科为商用交换芯片厂商,思科和英伟达为自用交换芯片厂商。展望未来,我们认为商用交换芯片的占比或将逐渐提高,原因在于:1)自研交换芯片需要高额研发投入和快速迭代,较难实现经济效益;2)以太网交换芯片的主要增量来自于数据中心市场,而商用厂商在此布局更早,具备先发优势;3)由于国际贸易摩擦引起的产业链震荡,商用交换芯片厂商对于产业链协调和产能紧缺的风险抵御能力更强。
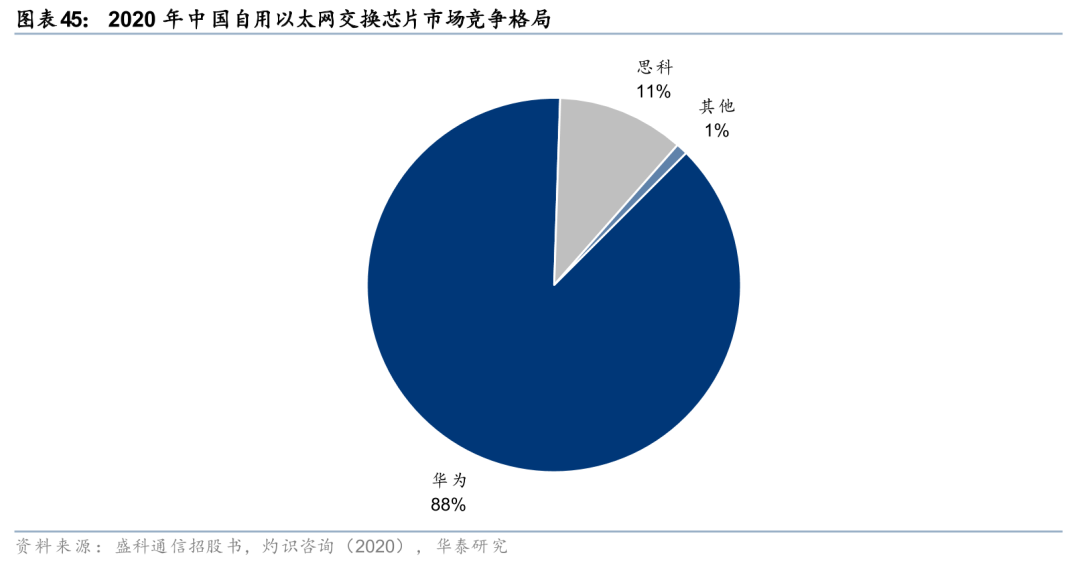
国内格局-自用:中国自用以太网交换芯片市场的主要参与者为华为和思科。根据灼识咨询数据,2020年中国自研以太网交换芯片市场以销售额口径统计,华为和思科分别以88.0%和11.0%的市占率排名前两位,合计占据了99.0%的市场份额。
国内格局-商用:国内商用交换芯片高度依赖于博通等海外巨头,国产厂商替代空间广阔。交换芯片行业进入壁垒高,一方面在于芯片集成度、复杂度日益提升,需要长期的技术积累和研发投入,另一方面在于芯片进入供应链后生命周期长达8-10年,具备较高的客户粘性。由于海外巨头进入国内交换机供应链时间较长、技术实力雄厚,因而占据大部分份额,具体来看:根据灼识咨询数据,2020年中国商用以太网交换芯片市场以销售额口径统计,博通、Marvell和瑞昱市占率分别为61.7%、20.0%、16.1%,国产厂商盛科通信市占率1.6%,位列全球厂商第四、境内厂商第一;2020年中国商用万兆及以上以太网交换芯片市场以销售额口径统计,博通、Marvell和Realtek市占率分别为73.1%、15.3%、9.0%,国产厂商盛科通信市占率2.3%,位列全球厂商第四、境内厂商第一。
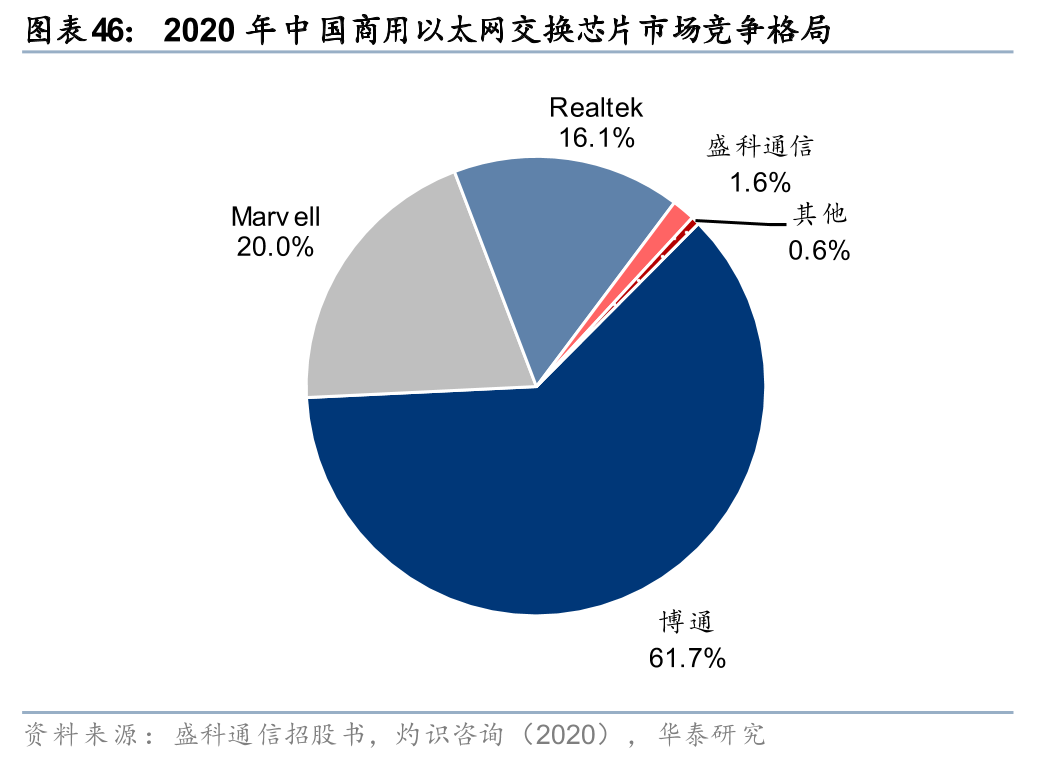
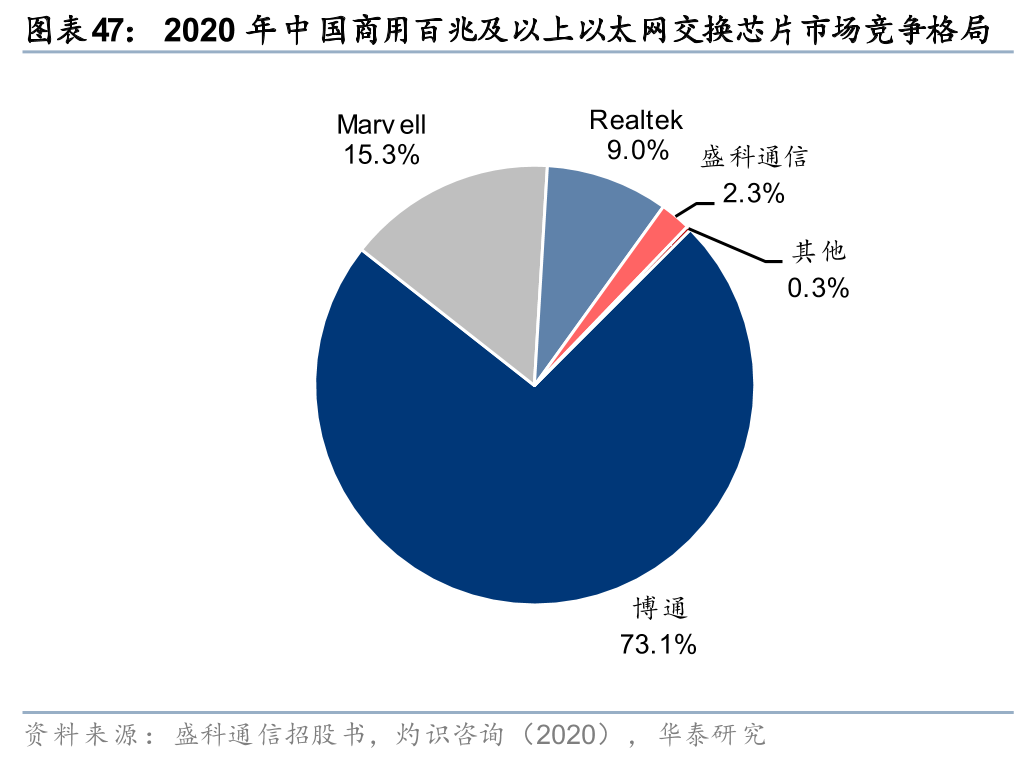
展望:随着国产超节点起量,国产交换芯片厂商或凭借本土化优势脱颖而出。超节点作为支撑万卡集群性能演进的系统级工程,其整体性能不仅取决于单卡算力,更在于网络、连接器件等各个层次厂商的紧密协作。我们认为,超节点或重塑国内交换芯片市场格局:1)超节点架构相对传统节点,其Scale up网络的作用被放大,而由于Scale up赛道目前全球尚未形成稳定的格局,协议标准也并未统一,国产厂商实际上与博通等海外巨头处于同一起跑线;2)区别于英伟达的封闭协议(NVLink),国内有望跑出如UALink、ETH、ALS等开放互联标准,而这一过程离不开CSP、GPU厂商、交换芯片厂商的深度协同;3)超节点的复杂性要求交换芯片与GPU进行深度的底层适配,本土厂商在底层架构开放及现场调试响应上更具优势,也更具配合意愿。
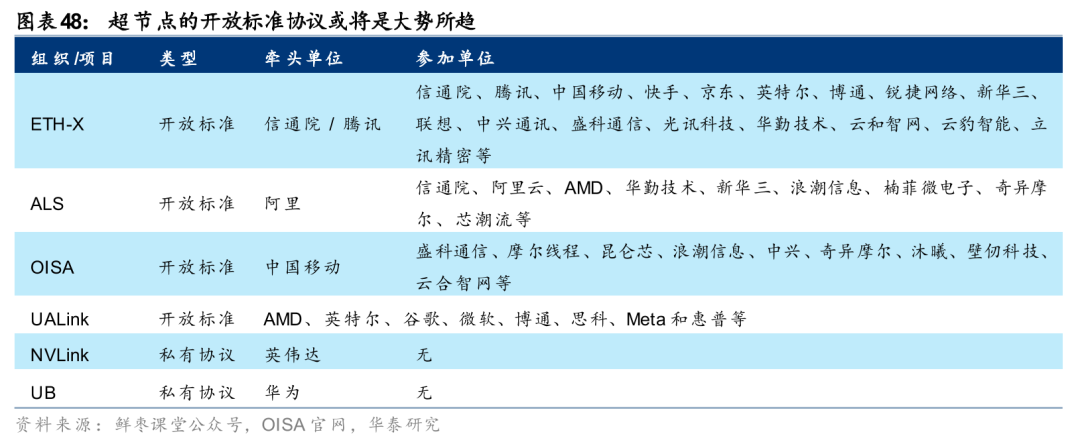
投资逻辑:关注海外龙头及技术领先的国产芯片商
展望未来,我们看好:1)北美云厂商及国内互联网厂商对未来的资本支出延续乐观,数据中心建设或将增加对交换机等网络设备的需求;2)超节点方案有望在追赶海外算力的背景下规模放量,其中Scale up是核心增量环节,交换芯片用量有望大幅提升。建议关注具备引领作用的海外龙头厂商以及技术领先的国产芯片商,我们梳理产业链如下:
海外厂商
博通(AVGO US)
博通成立于1991年,总部位于美国硅谷。博通是全球领先的有线和无线通信半导体公司,为计算和网络设备、数字娱乐和宽带接入产品以及移动设备的制造商提供业界最广泛的、先进的SoC和软件解决方案。公司产品应用于高、中、低端产品线,主要发展高端产品线,主要资源投入在面向超大规模数据中心的Tomahawk系列以及Trident系列等高性能系列。目前,公司最高端产品Tomahawk 6交换容量达到102.4Tbps,最高可支持64个1.6TbE端口,可用于搭建512颗XPU的超节点以及十万卡集群。得益于先进的产品性能,公司在全球范围内长期处于行业龙头地位。
Marvell(MRVL US)
Marvell成立于1995年,总部位于美国硅谷,公司是一家提供全套宽带通信和存储解决方案的全球集成电路设计厂商,主要从事混合信号和数字信号处理集成电路设计、开发和销售,产品线涵盖嵌入式处理器、无线通信芯片、车载电子、以太网控制器、存储器、转换器、服务器处理器等众多种类。2021年8月,Marvell收购主营云服务器以及边缘数据中心以太网交换芯片的集成电路设计企业Innovium,通过其以太网交换芯片产品Teralynx 系列切入超大规模数据中心等高端领域。公司于2023年3月推出Teralynx 10以太网交换芯片,交换容量51.2Tbps,可支持64个800GbE端口。公司于2024年7月宣布Teralynx 10进入量产及客户部署阶段,针对数据中心及AI网络的进行优化,具备大带宽、超低延时、低功耗、512端口以及线速可编程等优势。
英伟达(NVDA US)
英伟达成立于1993年,总部位于美国硅谷。英伟达主要从事GPU的设计和制造,产品应用于游戏、专业可视化、数据中心和自动驾驶等领域,在AI领域处于领先地位。英伟达从事以太网交换芯片行业的子公司为Mellanox,于2020年被英伟达收购,Mellanox的端到端解决方案包括适配器、网关和交换机、集成电路、适配卡、交换机系统等。在Scale out领域,公司同时推进Infiniband和以太网两种方案,Infiniband协议对应Quantum系列交换机,最新代交换芯片Quantum-X800 ASIC,采用台积电4nm工艺封装,通过CPO技术集成6个光学子组件,交换容量为28.8Tbps;以太网协议对应Spectrum系列交换机,最新代交换芯片Spectrum-6的交换容量达到102.4Tbps,通过CPO技术将32个1.6 Tb/s硅光光学引擎与交换芯片直接封装集成,支持128个800G端口。在Scale up领域,公司基于NVLink协议实现单节点内部的多个GPU全互联,最新代交换芯片NVSwitch 5.0支持GPU间的3.6TB/s双向带宽,提供7.2TB/s的无阻塞交换容量。
思科(CSCO US)
思科成立于1984年,总部位于加利福尼亚州圣何塞,公司生产了世界上第一台交换机和路由器,并始终在全球网络设备市场保持领先。公司为客户提供集成网络的解决方案,涵盖设计、生产、销售基于互联网协议(Internet Protocol)的网络产品及其它通信和IT产品及服务。公司于2023年6月发布Silicon One G200/G202交换芯片,G200采用5 纳米制程,交换容量达到51.2Tbps,可支持64个800Gb端口,具备高稳定性、低延迟、可编程等特性;G202特性与G200类似,但性能仅是其一半,即交换容量25.6Tbps。公司于2026年2月发布Silicon One G300交换芯片,交换容量达到102.4Tbps,最高可支持64个1.6T端口,相比上代产品G200和竞争产品,G300网络利用率提升33%,作业完成时间缩短28%。
国内厂商
1. 云厂商资本开支投入不及预期;数据中心需求同云厂商资本开支相关,若云厂商放缓资本开支投入,对于数据中心的需求将产生影响。
2. 超节点方案落地进程不及预期;超节点架构强化了Scale up网络的重要性,催生了大量的Scale up交换芯片需求,若后续因技术水平、关键设备供应等因素导致超节点落地时间延后,则将影响交换芯片行业规模的增长。
3. 本研报中涉及到未上市公司或未覆盖个股内容,均系对其客观公开信息的整理,并不代表本研究团队对该公司、该股票的推荐或覆盖。

 VIP复盘网
VIP复盘网
